


















咨询服务热线:400-0698-860
电话:027-5972 8168
邮箱:info@chaoqing-i.com
总部:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼
北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911





在人工智能技术飞速发展的当下,大模型以其强大的语言理解和生成能力、数据处理能力以及智能分析能力,为政企单位的业务创新和升级提供了无限可能,成为推动各行业创新与变革的关键力量。
企业在将大模型应用于实际业务时,面临着部署难度大、算力需求高、部署复杂、运维困难等挑战,尤其在数据安全和隐私保护日益重要的背景下,企业对数据的自主管理和控制需求愈发迫切。
针对政企单位本地化部署需求,超擎数智推出擎天、锋锐、元景系列DeepSeek推理微调一体机产品,以卓越硬件配置、全流程开发支持、数据安全和隐私保护为核心优势,为不同行业用户快速实现DeepSeek本地化部署,高效构建基于DeepSeek的智能应用,实现业务的创新与升级,满足企业对数据私有化和自主可控的需求,助力客户快速实现AI技术赋能业务升级。

● 卓越硬件配置
单机最高可提供1128GB显存,可承载671B参数的DeepSeek-R1模型全量部署;
搭载擎天、锋锐、元景系列高性能服务器,支持多机并行推理,满足高并发业务需求。
● 全流程开发支持
覆盖数据治理、模型微调、推理服务到运维管理等AI 开发全流程服务;
提供开箱即用的AI开发工具和服务,降低技术门槛,缩短部署周期。
● 数据安全和隐私保护
通过私有化部署,将数据和应用部署在企业内部的基础设施上,从而实现数据的本地化存储和管理,确保企业数据的自主可控和安全合规。
擎天、锋锐、元景DeepSeek推理微调一体机已适配深度优化的DeepSeek大模型,可支持1.5B、7B、8B、14B、32B、70B、671B等规格的蒸馏模型以及原生大模型,依托超擎数智自研GPU服务器的硬件垂直优化与DeepSeek模型的深度适配,可大幅提升大模型的推理性能。
擎天系列DeepSeek推理微调一体机:部署1.5B-70B模型,采用FP16模型精度,推荐使用1台;部署671B满血版,采用FP8、FP16模型精度,推荐使用4台。
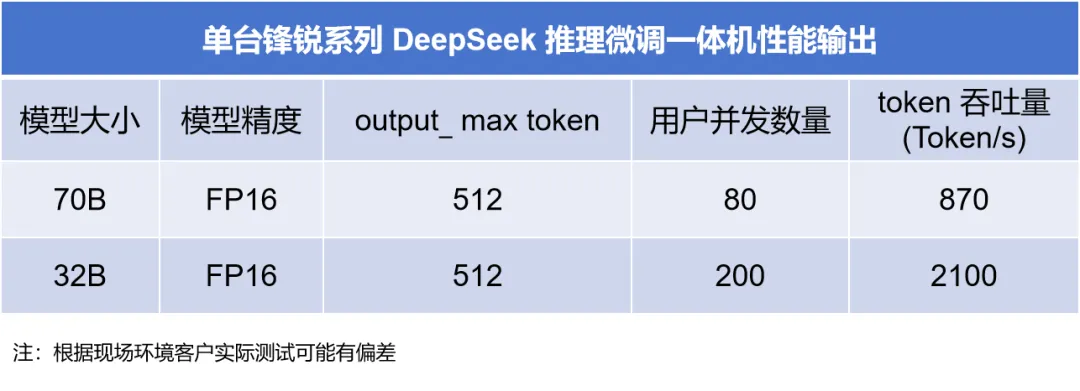
锋锐系列DeepSeek推理微调一体机:部署1.5B-70B模型,采用FP16模型精度,推荐使用1台。
元景系列DeepSeek推理微调一体机:部署671B满血版,采用FP8模型精度,2台(96G显存)用户并发数量为1024,token吞吐量为3113.38 token/s;1台(141G显存)用户并发数量为128,token吞吐量为1052.92 token/s。


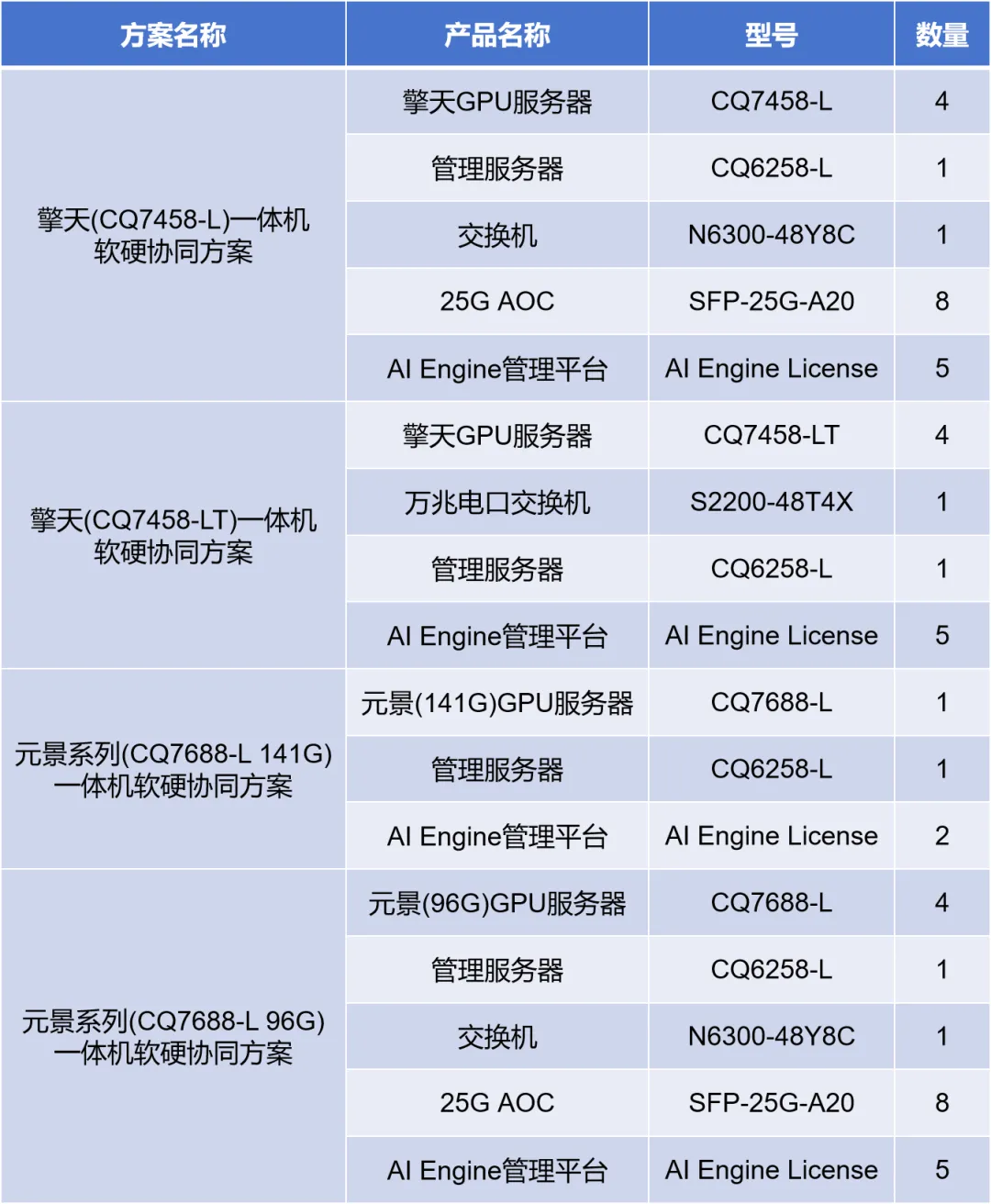
同时,针对行业用户需求,超擎数智推出专为大模型本地化部署打造的DeepSeek一体机软硬件协同方案,深度融合计算、网络与管理模块,为用户提供开箱即用的AI基础设施和服务支持。通过多节点协同、智能管理、高速互联,支持快速部署与灵活扩容,降低机房空间占用,轻松承载DeepSeek-R1(671B参数)等大模型全量部署。

超擎数智DeepSeek推理微调一体机与本地化部署服务,以低门槛、高性能、强安全、多场景的一站式解决方案,为用户构建高效、便捷、普惠的AI基础设施,将有力推动大模型在各行业的广泛应用,助力政企单位实现智能化转型与创新发展。

公众号


电话

需求反馈
