



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼


深度学习与人工智能解决方案
人工智能是引领新一轮科技革命和产业变革的战略性技术和重要驱动力量,与经济社会发展深度融合的前景广阔、潜力巨大。随着人工智能技术的持续迭代升级,其引领作用和潜在价值被逐步释放,人工智能在大模型、大数据、大算力领域的技术创新,带来了新一轮发展战略机遇,加速推动智能经济发展和产业数字化转型。
人工智能的成功需要大量的数据、存储和计算。IT已进入“AI大计算”的时代,为应对“AI大计算”带来的挑战,超擎以“计算+AI”战略为核心,提供先进的人工智能计算系统与解决方案,积极参与人工智能技术开源社区,与互联网、安防、医疗健康、金融、家居、机器人、自动驾驶等典型人工智能用户开展深入合作。超擎未来在人工智能领域将持续投入,为人工智能的长远健康发展贡献力量。
超擎数智全栈解决方案
超擎数智在人工智能计算领域拥有专业的产品技术团队和丰富的项目交付经验,持续为用户提供创新、高效、可靠的产品、解决方案与技术服务,致力通过创新的算力和网络方案成就客户,创造价值。
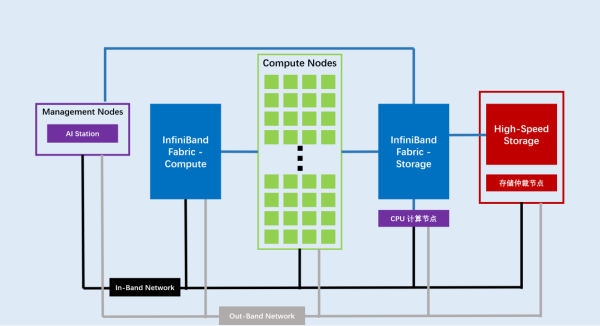
超擎数据中心计算集群解决方案
AI计算平台:深度学习计算设备
超擎 CQ7458-L是超擎为超大规模数据中心研发的同时拥有高性能,高兼容,强扩展的新一代PCIE5.0 AI服务器,定位是实现平台最大化性能、扩展性的 4U双路旗舰产品,灵活满足人工智能领域、数据中心多样化工作负载,作为4U双路产品中定位高端旗舰在4U空间内支持2颗Intel最新的SPR CPU和最高10片来自NVIDIA的DataCenter GPU。

领先科技:
2 颗 Intel SPR 处理器,采用先进工艺制程
最高支持10颗NVIDIA DataCenter GPU
支持多实例 GPU(MIG),大幅提升 GPU 资源利用率
支持最新DDR5 Memory,最高4800MT/s
优化设计:
可支持CXL Device,通过CXL扩展存储级内存
支持最新Hopper,Ada架构的GPU
模块化设计,操作灵活,便于运维
领先支持NVIDIA InfiniBand, NV-DPU, 等智能网卡
可靠品质:
支持硬/软RAID方案,保证数据安全
N+N冗余电源,保障系统可靠运行
优化散热设计,支持高环温下稳定工作
智能远程管理,快速定位故障
出色生态
广泛成熟的 x86+CUDA 全球开发生态
领先的深度学习框架支持,TensorFlow/PyTorch/ 飞桨等
高效支持大规模 CV/NLP/NMT/DLRM 模型训练和推理
AI计算平台:高速融合的网络系统
交换机
更快的服务器、高性能存储和日益复杂的计算应用正在将数据带宽要求推向新的高度。NVIDIA Mellanox QM9700 交换机提供具有极低的延迟,NVIDIA Quantum-2 采用第七代 NVIDIA InfiniBand 架构,可为 AI 开发者和科学研究人员提供超强网络性能和丰富功能,帮助他们解决充满挑战性的问题。NVIDIA Quantum-2 通过软件定义网络、网络计算、性能隔离、高级加速引擎、远程直接内存访问 (RDMA) 以及高达 400 Gb/s 的超快的速度,为先进的超级计算数据中心提供助力。

NVIDIA Quantum-2交换机
智能网卡
超擎在网卡侧提供NVIDIA ConnectX SmartNIC智能网卡,NVIDIA ConnectX InfiniBand 智能网卡支持更快的速度和创新的网络计算技术,实现了超强性能和可扩展性。NVIDIA ConnectX 降低了每次操作的成本,从而可为高性能计算 (HPC)、机器学习、高性能存储及数据库业务和低延迟嵌入式等应用提高投资回报率。来自 NVIDIA Quantum-2 InfiniBand 架构的 ConnectX-7 智能网卡(HCA)可提供超高的网络性能,用于处理极具挑战性的工作负载。ConnectX-7 支持超低时延、400Gb/s 吞吐量和创新的 NVIDIA 网络计算加速引擎,实现额外加速,为超级计算机、人工智能和超大规模云数据中心提供所需的高可扩展性和功能丰富的技术。

NVIDIA ConnectX 智能网卡
光模块与高速线缆
超擎提供灵活的NVIDIA 400Gb/s InfiniBand光连接方案,包括使用单模和多模收发器、MPO光纤跳线、有源铜缆(ACC)和无源铜缆(DAC),用以满足搭建各种网络拓扑的需要。
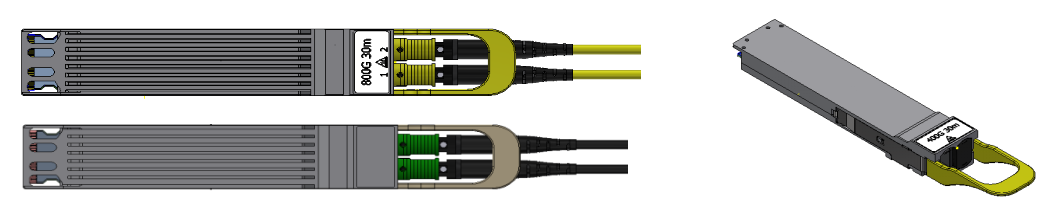

超擎是NVIDIA网络产品的Elite Partner,携手NVIDIA实现光连接+网络产品与解决方案的强强联合,尤其是在InfiniBand高性能网络建设与应用加速方面拥有深刻的业务理解和丰富的项目实施经验,可根据用户不同的应用场景,提供最优的InfiniBand高性能交换机+智能网卡+AOC/DAC/光模块产品组合方案,为数据中心、高性能计算、边缘计算、人工智能等应用场景提供更具优势与价值的光网络产品和整体解决方案,以低成本和出色的性能,大幅提高客户业务加速能力。
AI计算平台:完整的深度学习环境
深度学习的成功除大量标记的数据样本、深度学习模型与算法外,尤其需要高性能的系统平台的支撑。深度学习分为线下训练和线上识别两个部分,对于线下训练而言,可采用GPU/KNM+IB/100GE/200GE高速网络+分布式并行存储的高性能集群系统架构。由于训练需要的样本越来越多,如图像达到亿级、语音达到十万小时,其数据量将达到PB级,这将需要大容量、高带宽的高性能并行存储进行存储和快速读取样本数据;由于训练时间长,不仅需要GPU进行加速,而且需要大规模集群系统并行处理;对于有的模型,参数将达到十亿级,需要高带宽、低延时高速网络保证节点间参数快速更新,保证模型的收敛。对于线上识别,其需要成干上万节点对外提供服务,将面临功耗的巨大挑战,采用低功耗的FPGA架构构建线上识别平台将是一个不错的选择。
超擎深度学习系统平台架构
超擎针对深度学习的特点创建如下图所示的整体系统方案,将高性能的并行存储方案通过高速网络与计算加速节点互连,并提供数据服务。适合线下训练的计算加速节点采用高功耗、单精度浮点运算能力强的GPU,或者KNM计算加速卡,而用于线上识别的计算加速节点采用低功耗,INT8运算能力强的GPU,或者低功耗,定制了识别程序的FPGA。在计算节点运行如TensorFlow、Caffe、CNTK等深度学习框架,同时AIStation管理平台对深度学习框架提供任务管理、登录接口、参数调优等服务,并对节点和计算加速部件进行状态监控和调度等。这一整套平台将为顶层的人工智能应用APP提供支撑。

公众号


电话

需求反馈
