


















咨询服务热线:400-0698-860
电话:027-5972 8168
邮箱:info@chaoqing-i.com
总部:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼
北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911





服务器网卡(NIC)的主要功能是管理和处理网络流量。与日常生活中接触到的计算机网卡相比,服务器网卡通常要求更高的数据传输速度,如10G、25G、40G、100G甚至200G、400G。
现如今,在数据中心和云计算领域,25G以太网凭借其高性能带宽、低成本、低功耗、增强计算和存储效率等优势正迅速成为下一代数据中心主流趋势。
目前市场上主流的25G光纤网卡包括Intel英特尔XXV710系列,NVIDIA ConnectX-5 EN、ConnectX-6 Lx系列,和新增的Intel英特尔E810系列等。本文将会就Intel和NVIDIA这几个系列中4款热门的以太网卡型号:英特尔 XXV710-DA2、NVIDIA MCX512A-ACAT、英特尔 E810-XXVDA2、NVIDIA MCX631102AN-ADAT一一进行对比分析。
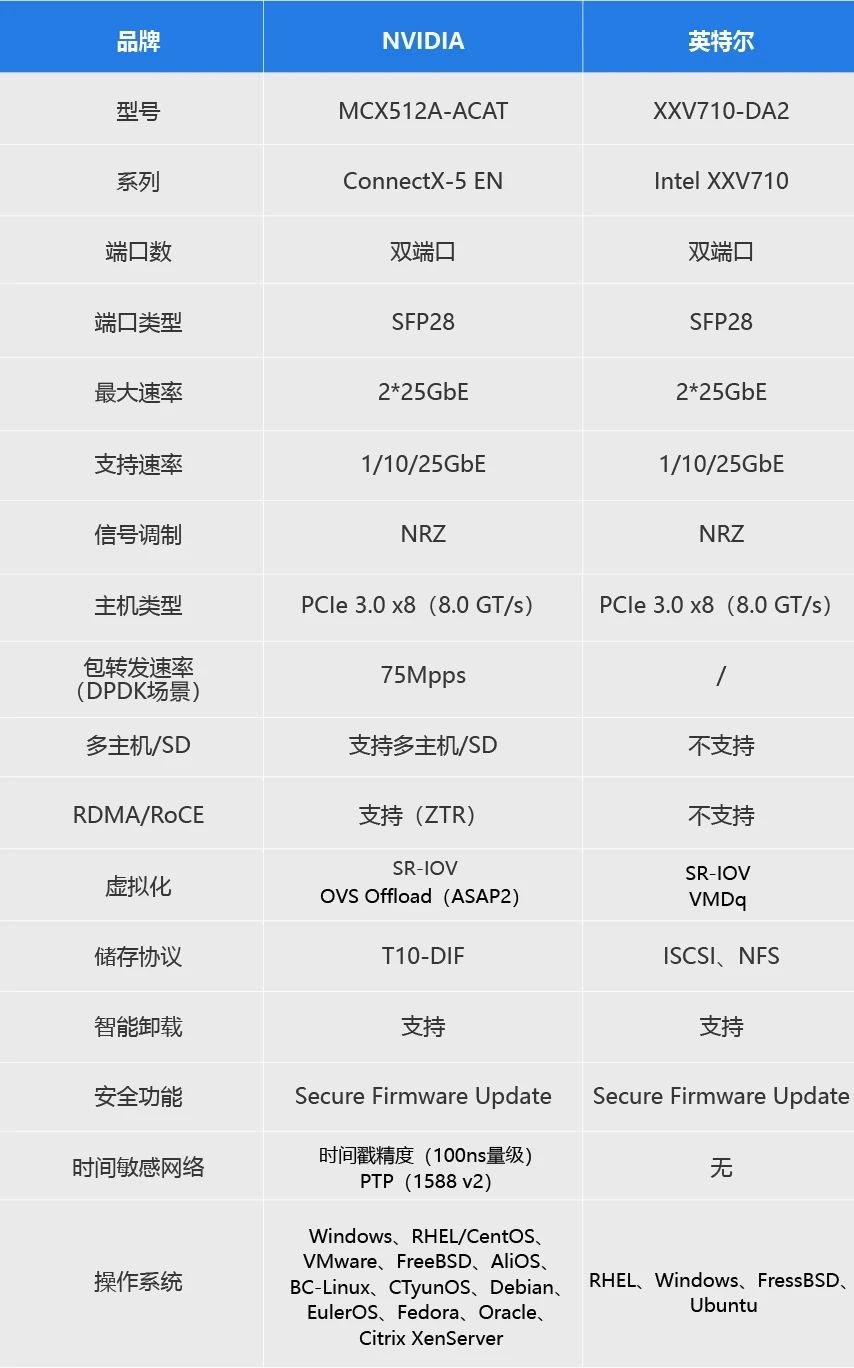
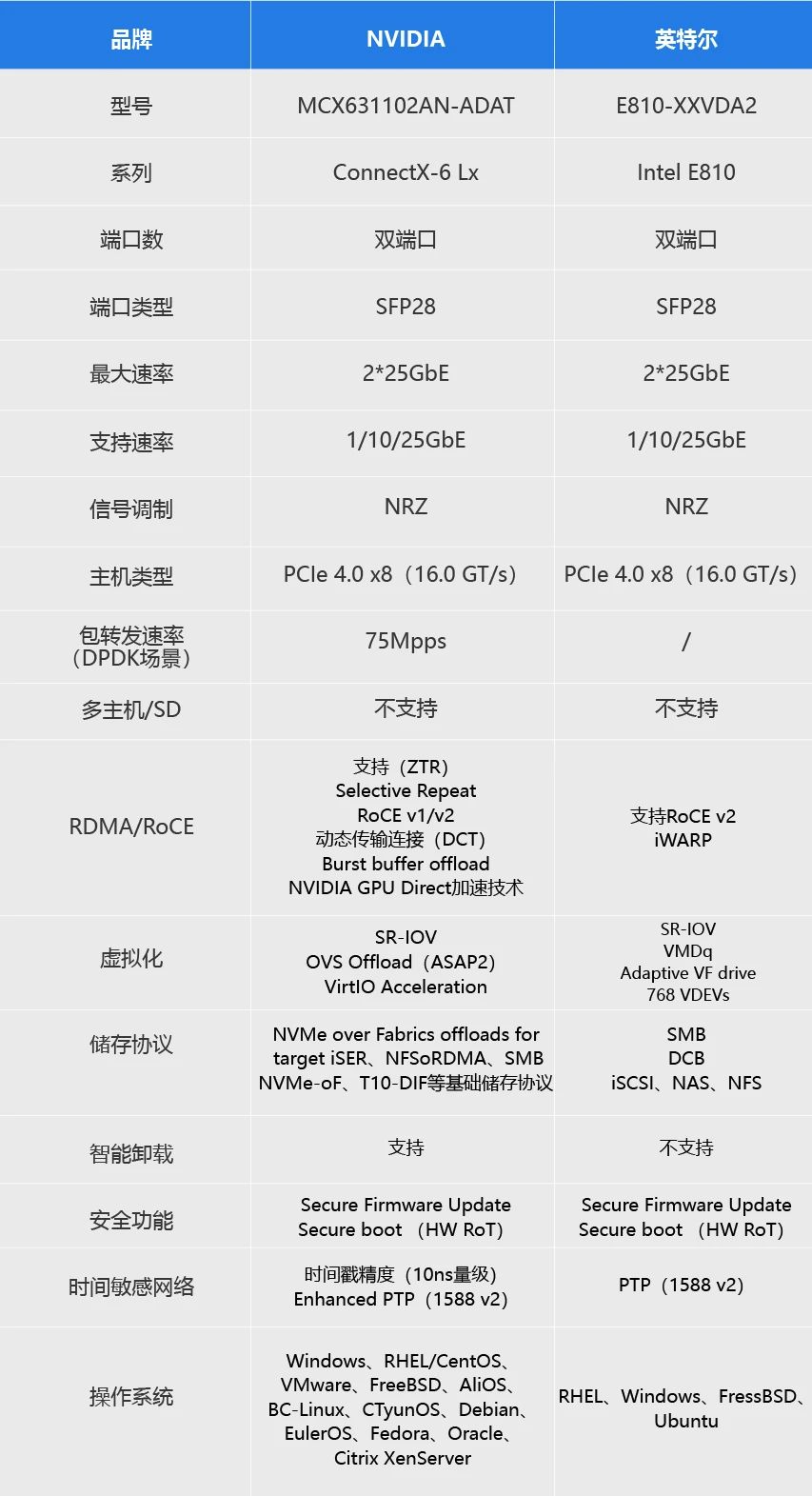
在高性能计算领域,光纤网卡作为服务器和网络设备连接的重要媒介之一拥有着众多复杂且必要的功能。这里我们将解释上文对比的4款25G网卡具有的一些常用功能。
RoCE:基于以太网的RDMA技术(RDMA over Converged Ethernet),目前有三种RDMA(远程直接内存访问)网络,分别是InfiniBand、RoCE、iWARP。
RoCE 和 iWARP都是基于以太网的RDMA技术,这使高速、超低延时、极低CPU使用率的RDMA技术得以部署在目前使用最广泛的以太网上。
RoCE是在InfiniBand Trade Association(IBTA)标准中定义的网络协议,允许通过以太网使用远程直接内存访问(RDMA)。它可以看作是RDMA技术在数据中心、云、存储和虚拟化环境中的应用。RoCE协议有RoCEv1和RoCEv2两个版本,RoCEv1是基于以太网链路层实现的RDMA协议(交换机需要支持PFC等流控技术,在物理层保证可靠传输),只允许在同一个二层网络中的主机进行通信,目前已使用较少。RoCEv2提供了基于三层网络的RDMA能力,数据包封装包含IP和UDP报文头,解决了扩展性问题,RoCE v2可以适配更多地通用网络场景。
iWARP:同样是允许通过以太网使用远程直接内存访问(RDMA)进行数据传输的网络协议。基于TCP的RDMA网络,利用TCP达到可靠传输。相比RoCE,在大型组网的情况下,iWARP的大量TCP连接会占用大量的内存资源,对系统规格要求更高。可以使用普通的以太网交换机,但是需要支持iWARP的网卡。
NVIDIA ZTR(Zero Touch RoCE):NVIDIA开发的ZTR技术,是一种具有往返时间拥塞控制的缩放零接触RoCE技术,能使数据中心无缝部署聚合以太网上的RDMA,而无需任何配置。数据中心运营商可以在无需任何交换机配置的情况下,享受部署和操作的便利性,以及大规模远程直接内存访问的卓越性能。实现了更具可扩展性、弹性且易于部署的RoCE解决方案。
Selective Repeat:选择性重传,RoCE Selective Repeat 在RoCE 中引入了一种新的QP重传模式,其中丢弃的数据包恢复是通过重新发送数据包而不是重新发送PSN窗口来完成的(Go-Back-N 协议)。这个功能在NVIDIA ConnectX6 Dx/Lx系列产品中默认支持。
动态传输连接(DCT):是一种通信模式,动态连接的传输服务是对传输服务的扩展,可实现RoCE网络更高程度的可扩展性,同时保持稀疏流量的高性能。
GPU Direct RDMA加速技术:NVIDIA PeerDirect 通信通过消除 PCIe 总线上组件之间不必要的内部数据复制(例如,从 GPU 到 CPU)提供了高效的 RDMA 访问,因此显著减少了应用程序运行时间。
OVS Offload(ASAP2,Accelerated Switching And Packet Processing ):Open vSwitch (OVS)是一个高质量、多层的虚拟交换软件,允许虚拟机 (VM) 相互通信并与外部世界通信。Offload数据平面到网卡芯片的eswitch,从而实现性能提升,并降低CPU开销。使用 ASAP2的开放式 vSwitch (OVS) 卸载,灵活的匹配动作流表,隧道封装/解封装。
SR-IOV:SR-IOV技术是一种基于硬件的虚拟化解决方案,可提高性能和可伸缩性。SR-IOV 规范定义了新的标准,根据该标准,创建的新设备可允许将虚拟机直接连接到 I/O 设备,越过了hypervisor与虚拟交换机层,这样可以带来低延迟和接近物理网卡的吞吐性能。SR-IOV是虚拟化的一个重要功能。启用SR-IOV的这个功能,将提高网络性能,降低网络时延等,为服务器内的虚拟机 (VM) 提供专用的适配器资源和有保证的隔离和保护。
VirtIO Acceleration:VirtIO是一种 I/O 半虚拟化解决方案,是一套通用 I/O 设备虚拟化的程序。virtIO Acceleration是网卡基于标准的virtIO驱动,基于硬件实现性能的优化提升。
VMDq:虚拟机设备队列(VMDq)是一项芯片级的技术,可以为基于软件的NIC共享创建并行队列,可以将网络I/O管理负担从hypervisor上卸载掉。
iSCSI:Internet小型计算机系统接口(Internet Small Computer System Interface),是一种基于IP的存储网络标准,在TCP/IP网络上通过发送SCSI命令来访问块存储服务。常用于内部网络的数据传输和远距离管理存储。
NVMe over Fabric(NVMe-oF):是一个相对较新的协议规范,旨在使用NVMe通过网络结构将主机连接到存储,支持对数据中心的计算和存储进行分解。NVMe over Fabric支持把NVMe映射到多种Fabrics的传输选项,包括前面提到的InfiniBand、RoCE和iWARP这三大支持RDMA的理想Fabrics。标准数据块和文件访问协议可以利用RDMA用于高性能存储访问以及用于目标机器的NVMe over Fabric卸载。
Data Integrity Validation (T10-DIF):是用户数据的一种端到端的保护机制,提供一种方法检查从主机总线适配器通过存储网络写到磁盘和读取回的数据的完整性。这种检查通过T10标准中定义的数据完整性字段来实现。
Intelligent Offloads(智能卸载):通过VMDq和灵活的端口分区等智能卸载,可以减少I/O瓶颈。将SR-IOV(单根I/O虚拟化)用于每个虚拟机(VM)的网络流量,从而实现接近本机的性能和VM可伸缩性。
FCoE:以太网光纤通道,是一种计算机网络技术。通过以太网网络封装光纤通道帧,允许光纤通道在保留其协议的同时使用10/25/40GbE以太网。
Secure boot(HW RoT): 通过HW RoT提供供应链保护,用于安全启动以及使用 RSA 加密和克隆保护的安全固件更新,通过设备唯一密钥,以保证固件的真实性。
通过上述两大主流品牌4款25G光纤网卡的对比,可以看出NVIDIA ConnecX-5 EN,ConnectX-6 Lx 在RoCE功能、虚拟化和容器化技术、储存协议、可支持的操作系统等能力上有更优的表现。NVMe over Fabrics存储卸载技术、加速交换和数据包处理(ASAP2)等等保障了高性能的可扩展网络,并兼容所有NVIDIA SmartNIC软件协议栈。结合ZTR(Zero Touch Roce),还可帮助用户在无需交换机配置情况下,快速实现零接触RoCE 部署,达到与传统无损RoCE解决方案相当的性能。
尤其是ConnectX-6 Lx,在25G网卡市场上,它延续了NVIDIA在网络方面的一贯创新,充分利用了软件定义和硬件加速等先进技术,将更多的安全和网络处理工作从CPU卸载到网卡上来,可在各种规模上提供强大的敏捷性和更高效率。ConnectX-6 Lx行业领先的RoCE和SDN加速功能为数据中心提供尖端的25GbE性能和安全性,是NVIDIA高性能以太网卡产品ConnectX网络适配器系列的成员。

公众号


电话

需求反馈
