



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





本文聚焦在NVIDIA L20上进行NVIDIA FP8 训练与推理的实践应用。FP8 训练利用 E5M2/E4M3 格式,这些类型可以将数学吞吐量翻倍,并将带宽压力减少一半,且具备与 FP16 相当的动态范围,适用于反向传播与前向传播。FP8 训练在相同加速平台上的峰值性能显著超越 FP16/BF16,并且模型参数越大,训练加速效果越好,且其与 16-bits 训练在收敛性和下游任务表现上无显著差异。FP8 训练通过 NVIDIA Transformer Engine 实现,仅需少量代码改动。支持 FP8 的框架包括 NVIDIA Megatron-LM、NeMo、DeepSpeed、飞桨 PaddlePaddle、Colossal AI、HuggingFace 等。
FP8 推理通过 NVIDIA TensorRT-LLM 实现,权重输入先转换为 FP8,并融合操作以提高内存吞吐,但部分输出仍需 FP16 进行 reduction。
FP8 基本原理、采用理由和收益
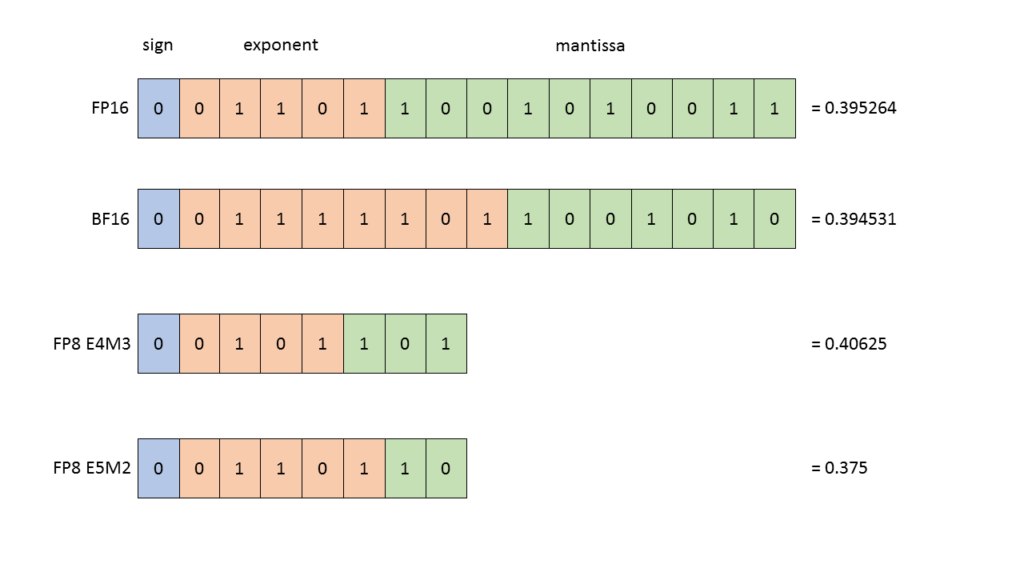
图 1. 在机器学习中四种常见的数据类型
首先详解 FP8 的概念,图 1 展示了 FP8、FP16、FP32 与 BF16 四种数据类型。业界曾长期依赖 FP16 与 FP32 训练,直至 GPT 横空出世,BF16 因能避免计算过程中的数值溢出问题而受到青睐。
近年来,NVIDIA 技术团队在 FP8 领域持续投入,发布了多篇论文,并在历届 GTC 大会也分享了 FP8 在计算机视觉 (CV)、自然语言处理 (NLP) 以及大模型训练中的实际效果。
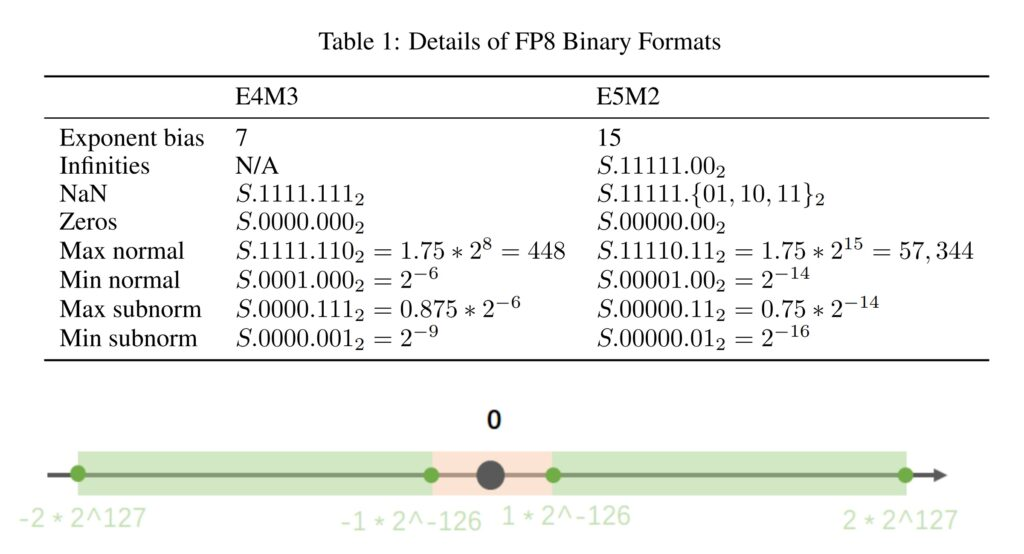
图 2. E4M3 与 E5M2 两种数据格式
FP8 数据类型实际上是 2 种不同的数据类型,可用于神经网络训练的不同部分:
E4M3 - 它由 1 个符号位、4 个指数位和 3 位尾数组成。它可以存储高达 +/-448 和 nan 的值。
E5M2 - 它由 1 个符号位、5 个指数位和 2 位尾数组成。它可以存储高达 +/-57344、+/- inf 和 nan 的值。增加动态范围的代价是存储值的精度较低。
图 2 详尽展示了 FP8 格式下各类特殊数值的表示方式。在训练神经网络期间,可以使用这两种类型。通常,前向激活和权重需要更高的精度,因此 E4M3 数据类型最适合在前向传递期间使用。然而,在后向传递中,流经网络的梯度通常不太容易受到精度损失的影响,但需要更高的动态范围。因此,最好使用 E5M2 数据格式存储它们。L20 TensorCores 支持将这些类型的任意组合作为输入,使我们能够使用其首选精度存储每个张量。
当我们考虑浮点数的数据精度会不会损失的时候,这个浮点数往往会落入图 2 下半部分里粉色的 subnormal 区间。图 2 下半部分是以 FP32 举例的,读者可根据图 2 表格看到 FP8 的 subnormal 区间,因此我们在训练模型时可进行理论分析,探究数值精度是否影响模型效果。

表1. L20的峰值性能测试数据
表 1 旨在阐述采用 FP8 的原因,以在 NVIDIA L20上为例,单位是 TFLOPS,相较 FP16 ,FP8 的峰值性能能够实现翻倍。
使用 Transformer Engine 训练 FP8 LLM
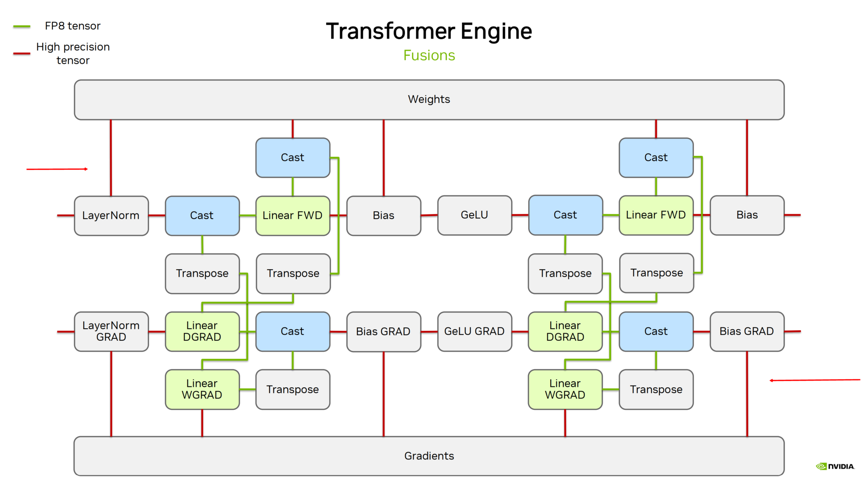
图3. FP8 训练在 Transformer Engine 上的完整流程
图 3 显示了训练中前向与反向计算的精度差异:红线表示高精度(BF16、FP32),绿线为FP8。在整个训练期间,图片上半部分的权重(weight)及下半部分的梯度(gradient)始终以高精度存储。仅在执行 linear 操作时,才对当前 tensor 进行数据格式转换(cast),转为 FP8 精度计算,但 linear 输出仍为高精度。因此,后续 bias 计算等均在高精度上进行。
图示表明,实际训练中仅 GEMM 计算采用 FP8,其余计算保持高精度。尽管业界存在对非线性操作也采用 FP8 计算和存储的激进策略,并在部分下游任务中表现良好,但主流方案依然遵循上述精细化的精度分配原则。
目前支持 FP8 训练的分布式训练框架与工具包括 NVIDIA Megatron-LM、NeMo 框架,DeepSpeed、飞桨 PaddlePaddle、Colossal AI、HuggingFace 等,也就是说这些框架均已集成了 Transformer Engine,可选用上述任一框架进行大模型 FP8 训练。
以NeMo框架为例,仅需在config或是在运行指令中设置精度为8,即可在FP8精度下进行训练,默认为使用FP16精度。
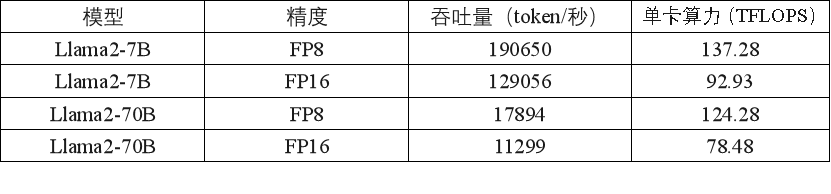
表2.L20 8卡8节点训练测试数据
表2展示了在8台机器上进行分布式运行训练不同规模的Llama2模型,模型规模参数分别为7B 和 70B,训练的Global Batch Size均为128。可以看到使用FP8相较于FP16进行训练的平均加速比为1.5倍,说明 FP8 训练的性能优化效果显著。
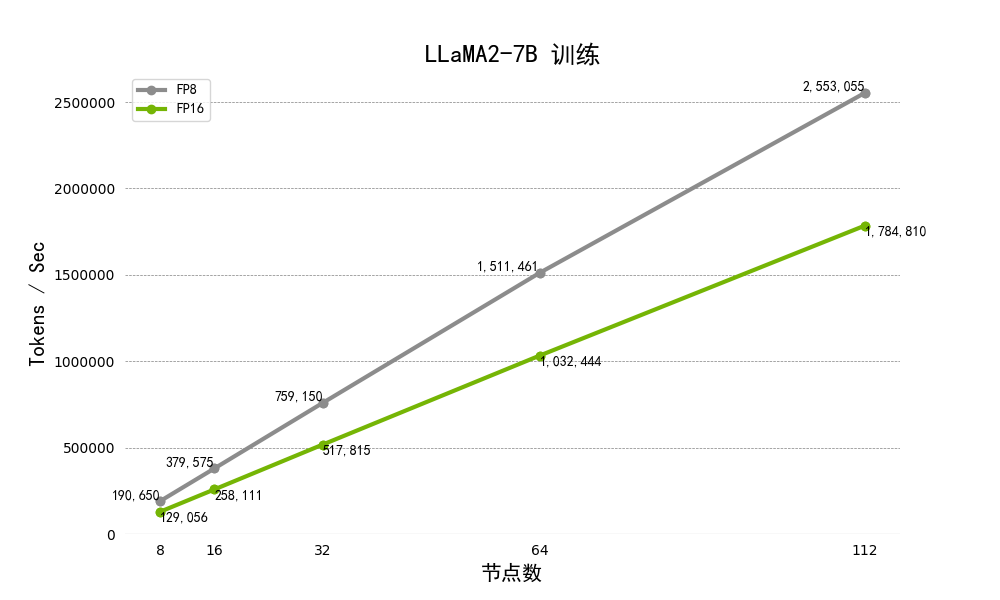
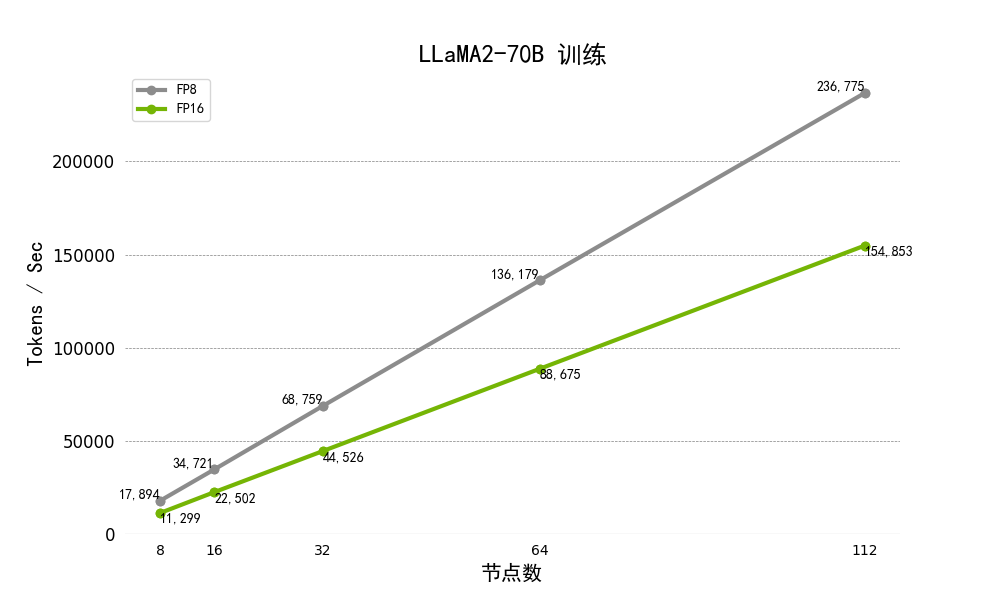
图4.多节点下进行Llama2-7B及70b模型训练的吞吐量
此外,我们在实际训练中可能产生的疑问解答如下:
1.目前广泛采用 BF16 进行混合训练,转用 FP8 是否需要自行编译 kernel 或进行复杂的数据类型转换?答案是否,建议使用 NVIDIA Transformer Engine 预置的多种 FP8 kernel(Linear、MLP、LayerNorm等基础算子及基于这些算子的fused kernel),无需开发,直接调用即可。
2.如果没使用 NVIDIA Megatron 或 DeepSpeed 框架,而是采用自定义框架,可以无缝使用 Transformer Engine 进行 FP8 训练吗?答案是可以。只需在 PyTorch 上使用 Transformer Engine 提供的 fp8_autocast 包装器 (wrapper),即可在原生 PyTorch 环境中开展 FP8 训练。此 wrapper 主要用于提供一系列 FP8-safe 的算子,自动将高精度的输入数据转换为 FP8,简化了低精度训练的实现过程。在上述过程中,需要对每个 tensor 更新其缩放因子 (scale),为此我们引入 amax(maximums of absolute value)的概念,fp8_autocast wrapper 会更新 amax 值。此外,根据 amax 值,该 wrapper 还会自动计算每个 tensor 的实际scale值。
3.Transformer Engine 除提供 FP8 layer-wise 模块和自动数据类型转换外,还有什么功能?答案是它还支持 FlashAttention 机制。这意味着 Transformer Engine 也能够提升传统 BF16、FP16 训练的性能。
4.对于已使用 BF16 训练的存量模型,能够使用 FP8 做继续训练吗?答案是可以。实践证明,BF16 格式的 checkpoint 可以直接导入进行 FP8 继续训练;反之亦然,即在预训练阶段使用了 FP8,那么在 SFT(supervised Fine-Tuning) 阶段,出于对模型精度或数据健壮性的考虑,仍旧可以从 FP8 无缝切换到 BF16 做继续训练。Transformer Engine 全面支持此类精度迁移的操作。
FP8 推理流程
我们使用 TensorRT-LLM 进行 FP8 推理。前文图 3 展示的 FP8 训练在 Transformer Engine 上的完整流程,而在进入推理阶段,图 3下半部分如梯度等训练特有部分可去除,仅保留上半部份即可。
训练时为确保梯度计算准确,权重通常维持为高精度(如 FP16 或 FP32),这是由于训练时需更新参数,而在推理时,权重已固定,故可在模型加载或预处理阶段提前将权重转换为 FP8,确保模型加载即为 FP8 格式。此外,推理阶段应尽量进行操作融合,如将 LayerNorm 与后续数据格式转换操作整合,确保 kernel 输入输出尽可能维持 FP8,从而能够有效提升 GPU 内存吞吐。同样,GeLU (Gaussian Error Linear Unit) 激活函数也要力求融合。
目前少量输出仍会保持为 FP16,原因是 NVIDIA NCCL 仅支持高精度规约操作 (reduction),所以现在仍然需采用 FP16 进行 reduction,完成后再转化为 FP8。
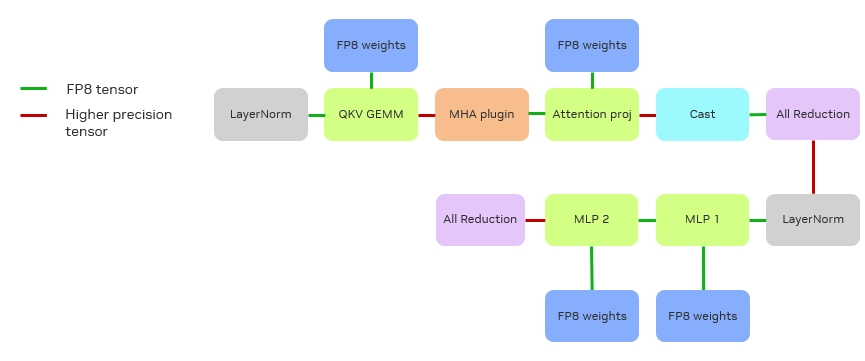
图 5. FP8 推理流程
经过上述融合后,推理流程就简化为图 5所示。绿线代表 FP8 的输入输出(I/O),红线表示高精度 I/O。图中可见,最前端的 LayerNorm 输出与权重均为 FP8,矩阵输出暂时保持 FP16,与前文描述一致。并且经过测试验证可得,虽然矩阵输出精度对整体性能影响较小,但与输入问题的规模相关;且因其计算密集特性,对输出形态影响微弱。
在完成 MHA(Multi-Head Attention)后,需要将结果转换为 FP8 以进行后续矩阵计算,Reduction 是以 FP16 执行后再转换到 FP8 的。对于 MLP1 和 MLP2,两者逻辑相似,但不同之处在于:MLP1 的输出可保持在 FP8,因为它已经把 GeLU 加 Bias 等操作直接融合到 MLP1 的 kernel。
实践:使用 TensorRT-LLM 实现 FP8 推理
TensorRT-LLM 是基于 NVIDIA TensorRT 构建,其 FP8 能力也主要是通过 TensorRT 提供。自 TensorRT 9.0 版本起,官方就已经开始支持 FP8 推理。要在 TensorRT 中启用 FP8 推理,需完成以下几步:
1.设置 FP8 标志:通过调用 config.set_flag (trt.BuilderFlag.FP8) 在 TensorRT 配置中启用 FP8 支持。类似 INT8、BF16、FP16,FP8 也是类似的启用方式。
2.添加 GEMM 缩放因子(scale):主要针对输入和权重,需在 weight.py (TensorRT-LLM 中的文件)中额外加载这些缩放因子。这是 FP8 推理中不可或缺的步骤。
3.编写 FP8模型:现阶段我们需要明确编写需要 FP8 支持的模型。具体做法如下:将原始 FP16 输入量化至 FP8,随后进行反量化;权重同样进行量化与反量化操作。如此编写的模型,TensorRT 会自动将量化与反量化操作尽可能与前一个 kernel 融合,以及将反量化操作与 matmul kernel 融合。最终生成的计算图表现为量化后的 X 与 W 直接进行 FP8 计算,输出也为 FP8 结果。
为了简化 FP8 在 TensorRT-LLM 中的应用,TensorRT-LLM 已对其进行封装,提供了 FP8 linear 函数和 FP8 row linear 函数来实现。对于使用直接线性层(linear layer),则无需重新编写代码,直接调用函数即可。
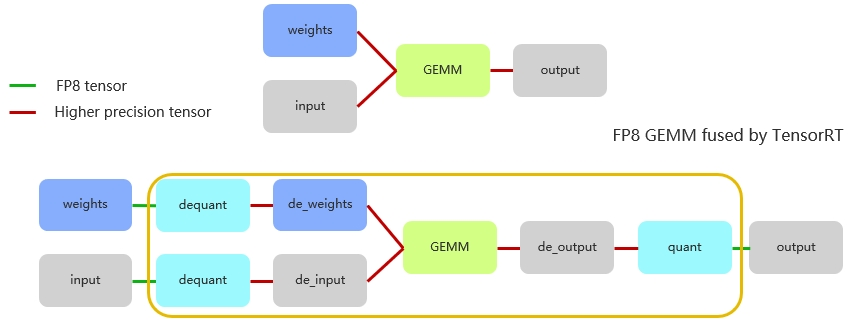
图 6. FP8 推理计算流程
本文用图 6总结上述内容。首先权重以 FP8 精度存储的,在进行计算前,权重先经历一次反量化。注意,在此之前,权重的量化已在输入前完成了,此处仅需进行反量化操作。这意味着,在进行矩阵内部计算时,实际上是使用反量化后的数据,通常是 FP16 或甚至 FP32来进行运算的。
矩阵层尽管以 FP8 表示,但累加是采用 FP32 完成,累加后再乘以 scale 的相关参数,形成如图所示的计算流程。最终得到的结果具备较高精度。由于累加器(accumulator)需要采用高精度的数值,因此,要获得最终 FP8 的输出结果,模型还需经过一个量化节点 (quantitation node)。
回顾整个流程,输入经历了量化与反量化操作。其中,量化 kernel 发生在反量化 kernel 之前,而 TensorRT 则会智能地融合这些 kernel,确保计算的高效和准确。
使用 Tensor-LLM 实现 FP8 推理的性能
python3 benchmark.py -m llama_7b --max_batch_size 24 --max_input_len 2048 --max_output_len 128 --input_output_len "2048,128" --batch_size "1;4;8;16;24" --quantization 'fp8' 2>&1 |tee log/trtllm_llama7b_2048_128_fp8_mbs24.log
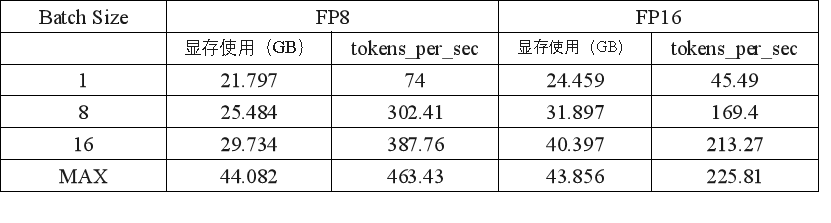
表 3. L20推理测试数据
表 3 对比第一列不同的 batch size,其中设定最大输入长度为 2048,最大输出长度为128,模型为Llama2-7B。
列表中,FP16 的MAX Batch Size为 24,而 FP8 的MAX值则提升至42。在相同的batch size下,FP8比FP16显著减少了显存的占用,显存使用的减少意味着可以在相同的硬件条件下处理更大的batch size或部署更复杂的模型。在性能方面,FP8在推理速度上显示出显著的优势,尤其是在较大的batch size下,速度提升更加明显。FP8允许更大的最大batch size这进一步证明了FP8在显存利用和处理能力上的优势,能够在同等条件下处理更多的数据。
总结
我们在L20显卡上进行了实验,以评估FP8在实际应用中的可行性和性能表现。研究结果表明,使用FP8进行训练和推理可以在不显著损失模型精度的前提下,大幅提升计算效率和资源利用率。特别是对于大型语言模型和深度学习任务,FP8展示了较大的潜力,能够显著降低硬件需求和能耗。
本文还讨论了FP8数值表示的实现细节、量化策略以及在训练过程中的稳定性问题。通过对比FP8和FP16性能,我们进一步验证了FP8在深度学习领域的应用前景。总结而言,FP8提供了一种高效且可行的解决方案,为深度学习模型的训练和推理带来了新的可能性。

公众号


电话

需求反馈
