


















咨询服务热线:400-0698-860
电话:027-5972 8168
邮箱:info@chaoqing-i.com
总部:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼
北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911





英伟达在6月3日的COMPUTEX大会上宣布了对广大开发者开放了NVIDIA NIM推理微服务的下载。这篇文章将从相关介绍,使用方法以及体验感受几个方面让您快速了解NIM。

什么是NIM?
NVIDIA NIM(Inference Microservices) 是 NVIDIA AI Enterprise 的一部分,它是一组易于使用的推理微服务,可加速在任何云或数据中心部署基础模型,并有助于确保数据安全。NIM 具有生产级运行时,包括持续的安全更新。使用由企业级支持支持的稳定 API 运行您的业务应用程序。
这些新的生成式 AI 应用程序变得越来越复杂,并且经常使用具有不同功能的多个模型来生成文本、图像、视频、语音等。NVIDIA NIM 通过提供一种简单、标准化的方式将生成式 AI 添加到应用程序,大大提高了开发人员的工作效率。
NIM 还使企业能够最大限度地利用其基础设施投资。例如,在 NIM 中运行 Meta Llama 3-8B 可以在加速基础设施上产生比没有 NIM 时多 3 倍的生成式 AI token。这让企业能够提高效率并使用相同数量的计算基础设施来生成更多响应。

超过 40 个 NVIDIA 和社区模型可在 ai.nvidia.com 上作为 NIM endpoints体验,其中包括 Databricks DBRX、Google 的开放模型 Gemma、Meta Llama 3、Microsoft Phi-3、Mistral Large、Mixtral 8x22B 和 Snowflake Arctic。
NIM的目标
人人都可以成为生成式AI开发者。
可扩展部署,性能卓越,可以轻松无缝地从几个用户扩展到数百万。
高级语言模型支持,具有预生成的优化引擎,适用于各种尖端 LLM 架构。
灵活集成,可轻松将微服务纳入现有工作流程和应用程序中。为开发人员提供 OpenAI API 兼容的编程模型和自定义 NVIDIA 扩展,以获得更多功能。
使用方法
官方网站:Try NVIDIA NIM APIs
官方提供api快速部署,支持通过python,js,shell的访问方式。使用点数,每次生成耗费一次,普通用户只有1000次,NVAIE用户可以增加到5000次且有更多的企业相关支持。实际使用时,生成时存在更高的延迟,部分模型目前有使用次数限制,且试用时可能会出现排队等待现象。
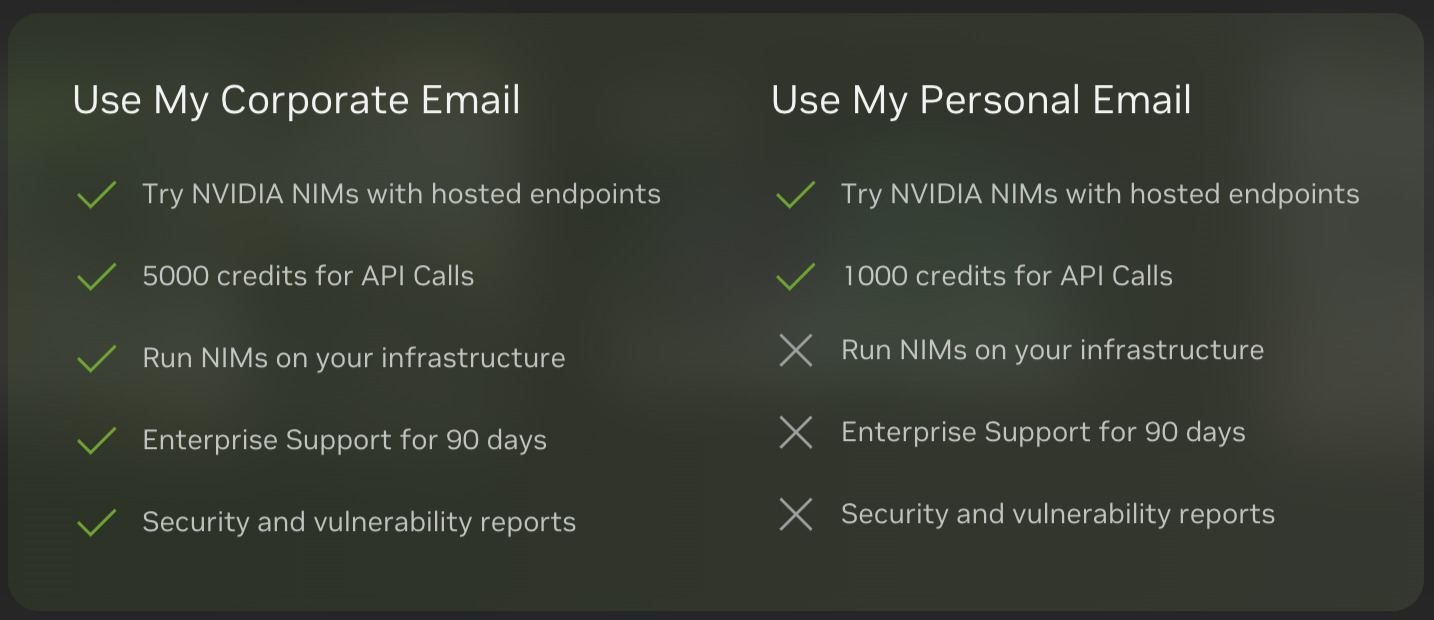
NVAIE用户可以在本地通过使用Docker进行模型部署。首次部署 NIM 时,NIM 会检查本地硬件配置和模型注册表中可用的优化模型,然后自动为可用硬件选择最佳版本的模型。对于部分 NVIDIA GPU(请参阅支持列表),NIM 会下载优化的 TRT 引擎并使用 TRT-LLM 库运行推理。对于所有其他 NVIDIA GPU,NIM 会下载未优化的模型并使用 vLLM 库运行该模型。
在本地使用同样支持API访问。生成速度更快,并且能够保证数据本地存储的安全性。
使用示例
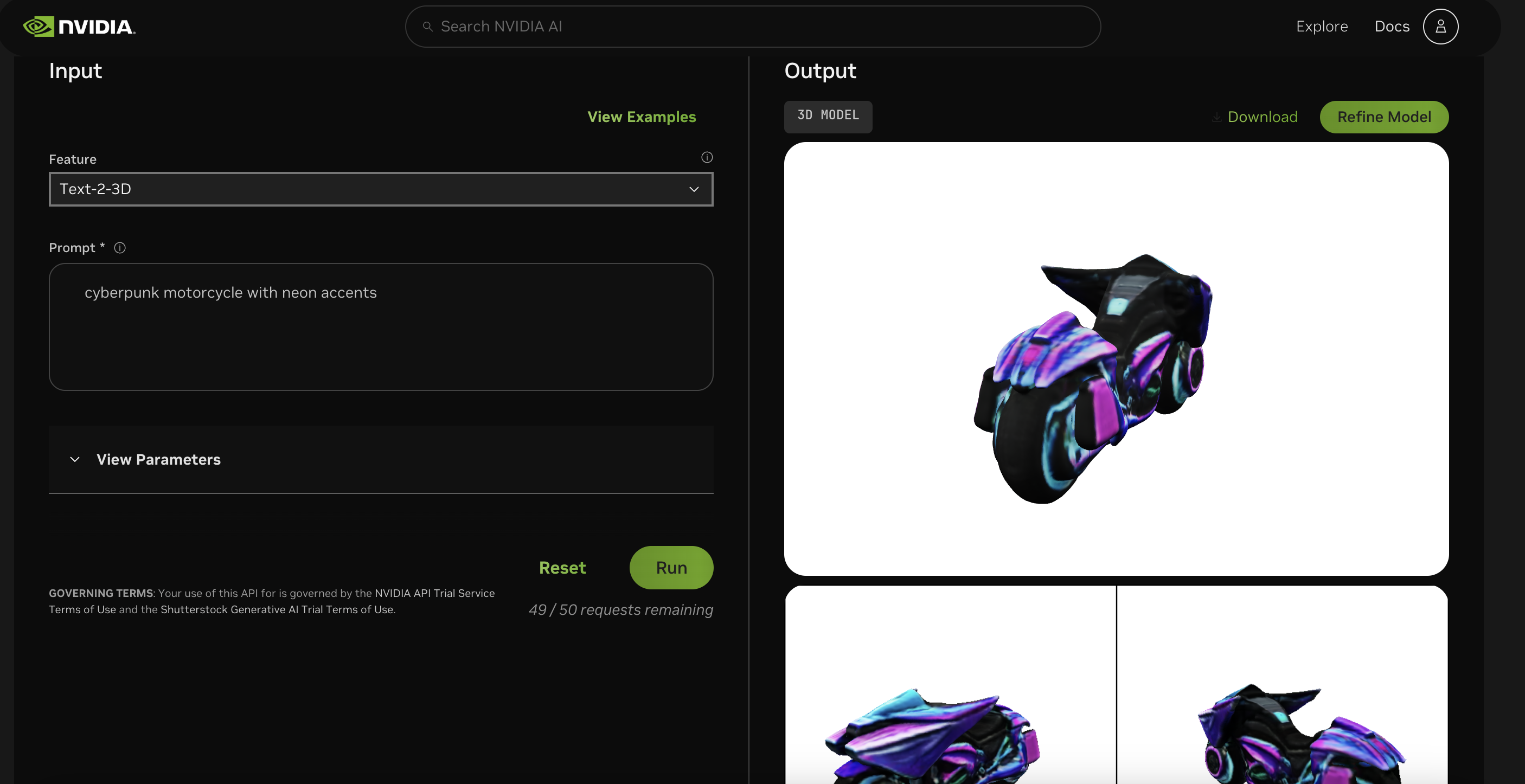
在官方网页中使用shutterstock 的edify-3d模型进行文生3D组件
NIM LLM
NIM for LLM 使 IT 和 DevOps 团队能够轻松地在自己的托管环境中自行托管大型语言模型 (LLM),同时仍为开发人员提供行业标准 API,使他们能够构建强大的副驾驶、聊天机器人和 AI 助手,从而改变他们的业务。
配置根据模型的需求和系统资源进行了调整,以最大程度地提高性能或满足特定的需求。对于部分显卡提供了单独的配置(FP8、FP16精度的选择):
该配置旨在最大化模型的吞吐量,即在单位时间内处理的样本数量。
通常,这种配置会牺牲一些延迟(latency),以换取更高的总体处理速度。
需要的GPU数量更小。
该配置旨在最小化模型的推理延迟,即处理单个样本的时间。
通常,这种配置会牺牲一些吞吐量,以换取更低的单个推理操作时间。
使用官方提供的API在本地结合Gradio使用的示例代码及Demo展示
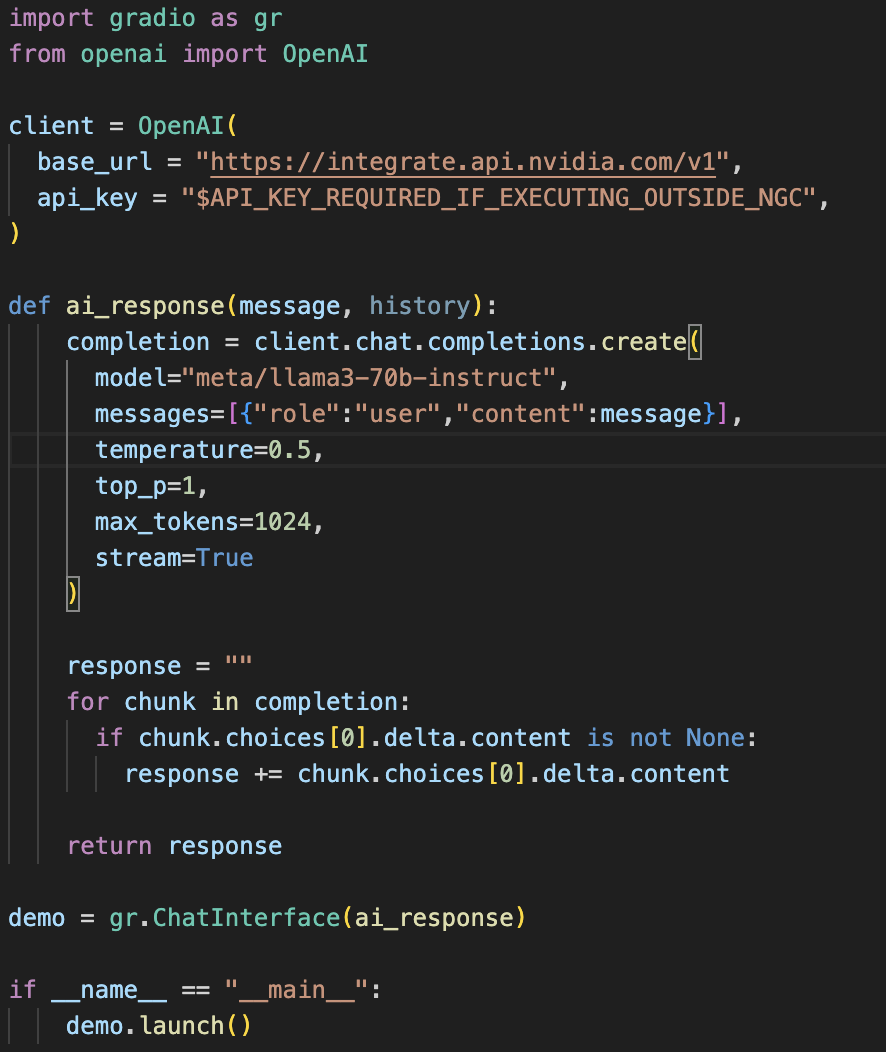
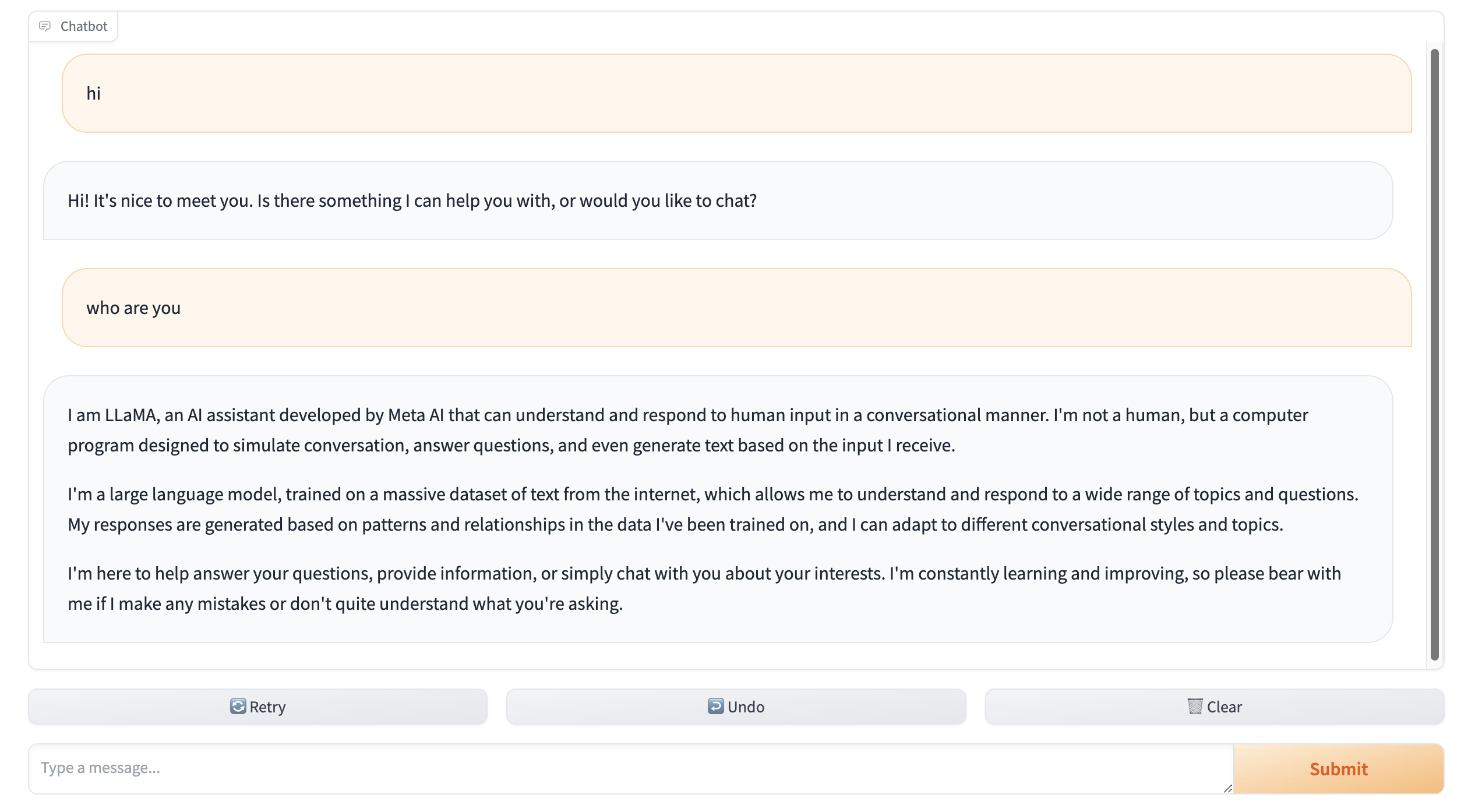
搭配超擎数智擎天系列L20 GPU服务器集群L20在本地使用Docker部署示例
docker run --restart always -it --name=$CONTAINER_NAME --runtime=nvidia --gpus all --shm-size=16GB -e NGC_API_KEY -v "$LOCAL_NIM_CACHE:/opt/nim/.cache" -u $(id -u) -p 8001:8000 $IMG_NAME
运行后可以通过以下指令检查当前运行模型的信息:
本地Docker部署结合Gradio使用的示例代码及Demo展示
推理性能对比(非标准测试及准确数据对比,与实际体验相结合)
NIM使用TensorRT-LLM架构进行推理。这里使用的是Llama3-8b-instruct模型,在FP16精度下,采用NIM自动识别的双卡配置。
由于NIM官方并未提供Batchsize数据,这里以输入128 tokens输出2048 tokens为例:
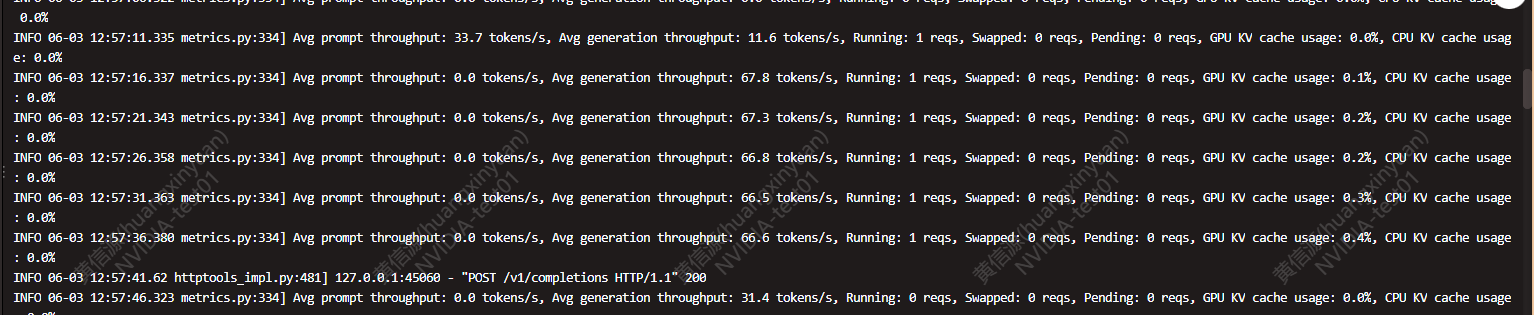
使用两块L20 进行TensorRT-LLM推理测试时的情况:
Batchsize设定为32
![]()
Batchsize 48
![]()
由输出结果可见NIM生成速度存在大幅优势
NIM支持多lora适配器微调
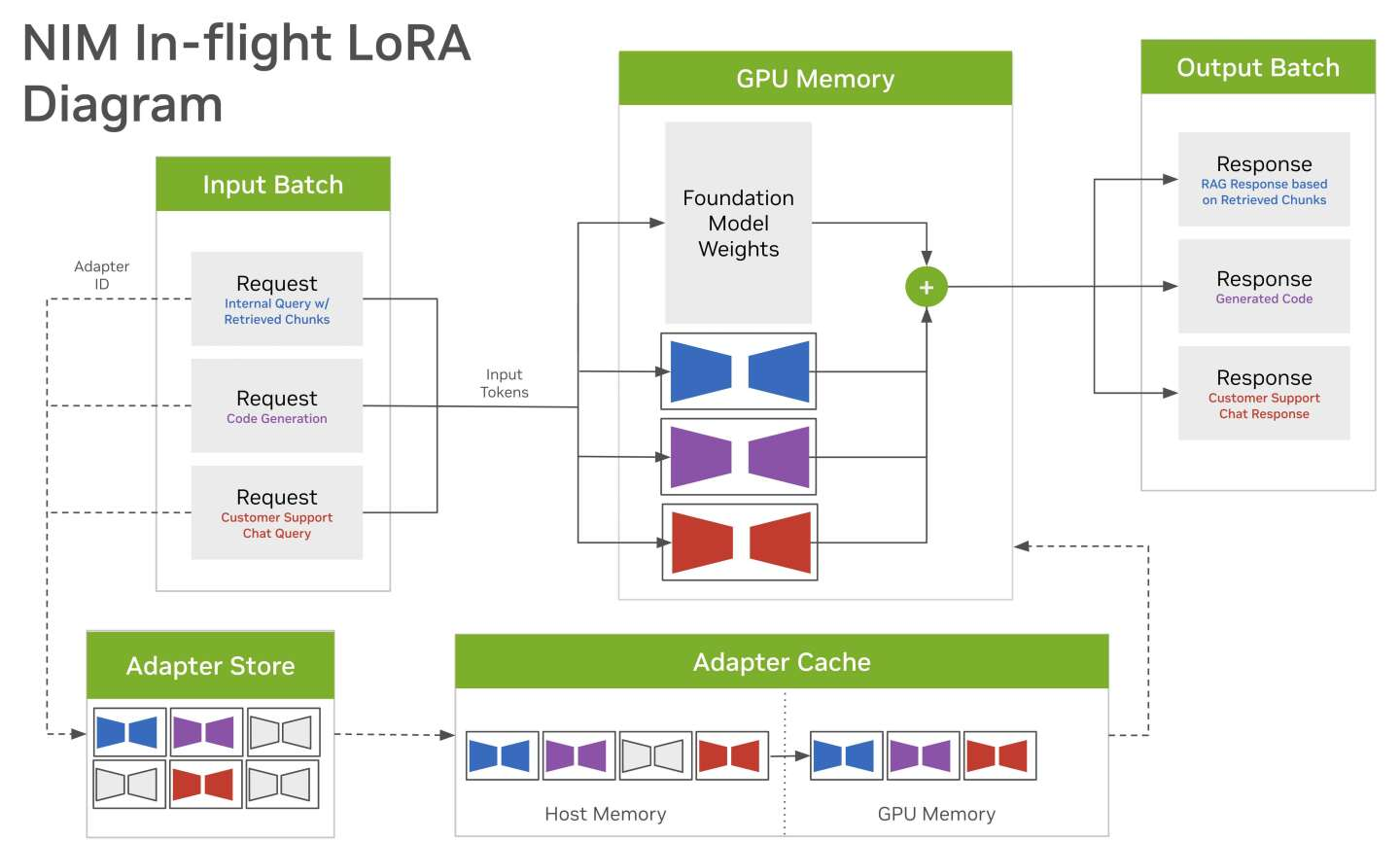
动态多 LoRA 推理
1. 支持多 LoRA 适配器:
不同的请求可以使用不同的 LoRA 模型进行处理,从而在同一基础模型上实现多任务处理。
LoRA 适配器通过低秩分解来减少参数量,从而使得在大模型上进行高效的微调和推理成为可能。动态加载和缓存机制确保了不同任务请求的高效处理。
通过适配器存储和缓存,NIM 可以根据需求动态加载和卸载 LoRA 适配器,从而优化内存和计算资源的使用。
适配器加载流程
根据请求内容和任务类型,选择合适的 LoRA 适配器。
2.适配器加载:
如果适配器不在缓存中,则从适配器存储中加载到缓存中。
使用基础模型权重和加载的 LoRA 适配器权重进行推理,生成输出。
将推理结果形成输出批次,并返回给相应的请求。
使用感受
完全本地运行确保数据安全;硬件环境要求低;部署迅速,速度快效率高,大幅降低开发周期;支持多Lora插件微调发挥更大潜力;可以搭配多个模型形成AI工作流;能并行处理多任务;支持工业化以及专业领域(医疗健康为主)模型。
目前支持的模型仍较少,能够本地部署且功能完整的模型只有Llama3;
与市面已知程序对比
目前市面用于快速部署模型应用的软件如ollama、gpt4all 都只适合个人用户或小规模使用。ollama在部署后也可以通过API访问和使用模型。ollama官方提供了热门模型的下载,也支持用户使用自己的模型。但NIM支持的数据精度更高为fp16或是fp8,ollama中仅可以使用量化过后的模型,精度大幅下降。且ollma在处理多用户、多任务下会出现阻塞等待现象,每次只能逐一处理单个输入,NIM在多用户输入下同样具有良好表现。gpt4all同样对于对请求处理存在问题,且只能进行使用聊天对话模型,无法提供api接口,不适用于软件开发或是企业应用。
未来可能的发展方向
聊天机器人和虚拟助手:为机器人提供类似人类的语言理解和响应能力。
情绪分析:实时了解用户情绪,推动更好的业务决策。
语言翻译:通过高效准确的翻译服务打破语言障碍。
结合NeMo从训练、微调到部署形成完整的开发工作。在一个节点运行一种模型,多节点、多种模型相组合形成完整工作流。在API访问的加持下更好的进行跨模型之间的数据访问。
完整的在本地使用NIM结合如Langchain架构进行数据检索,嵌入使用及最终部署RAG应用。速度更快,部署简单,本地化确保数据安全及完全私有化,适合企业内部员工问题检索或是客服机器人等相关应用。
NIM自身有对模型进行优化,部分专业模型部署可能相对复杂,且对环境有更高要求。如果未来NIM能够支持更多相关模型可以更快速的部署,且具有更好的效果和体验。构建AI工作流发挥更大价值。如工厂内部环境3D建模(omniverse)+最佳路径选择(目前NIM中有对cuopt一个用于复杂路线优化的模型支持)搭配进行机器人自动化寻路相关应用开发。

公众号


电话

需求反馈
