



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼






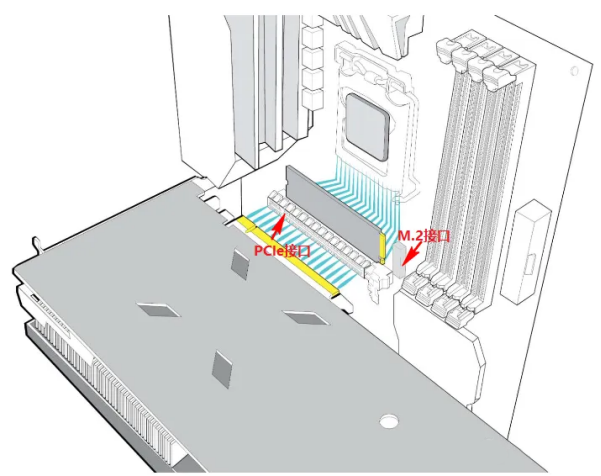
PCIe是PCI-Express (Peripheral ComponentInterconnect Express)的简称,它是一种内部总线,也是一种计算机扩展总线标准,是一种高速串行、高带宽扩展总线,通常用于主板上连接显卡、固态硬盘以及采集卡和无线网卡等外设。但是,PCIe不仅限用于主板上。在很多芯片与芯片之间的互连也采用的是PCIe的总线。
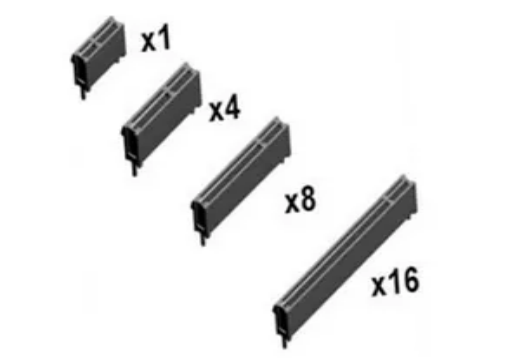
主板上的 PCIe 通道分为 x1、x2、x4、x8 和 x16 几种配置。通道数量越多意味着带宽越高,插槽也就更长。PCIe有两种存在形式:M.2接口通道形式和PCIe标准插槽。

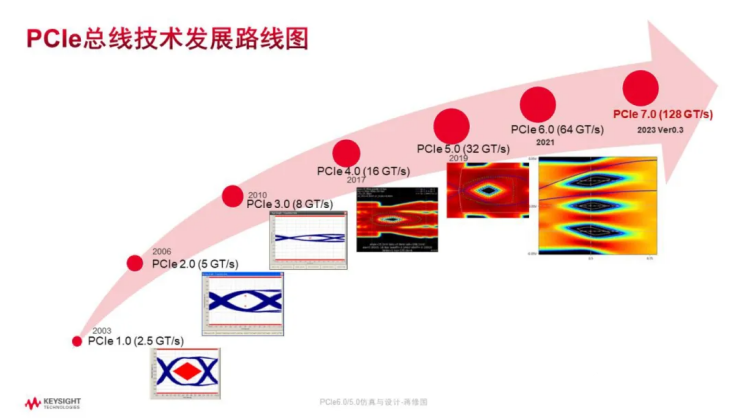
随着数据需求带宽的不断增加,PCIe发展也是越来越快,最近基本上是2年一升级。直到现在,PCIe 7.0 呼之欲出。
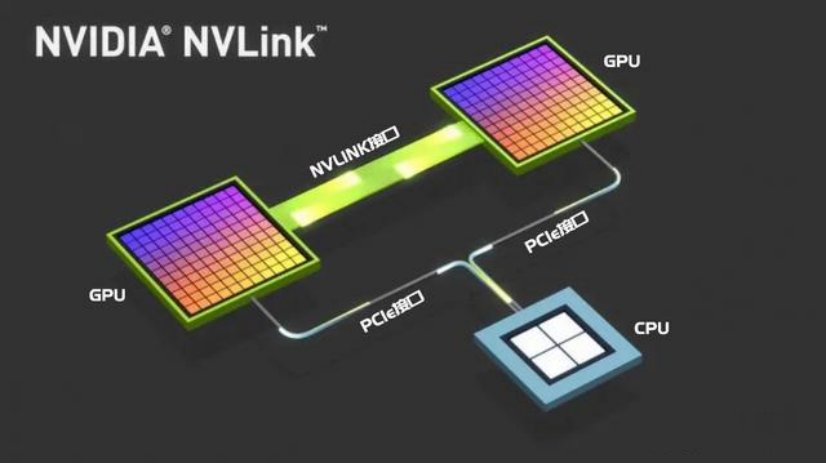
NVLink 是一种高速互连技术,旨在加快 CPU 与 GPU、GPU 与 GPU 之间的数据传输速度,提高系统性能。
NVLink通过GPU之间的直接互联,可扩展服务器内的多GPU I/O,相较于传统PCIe总线可提供更高效、低延迟的互联解决方案。
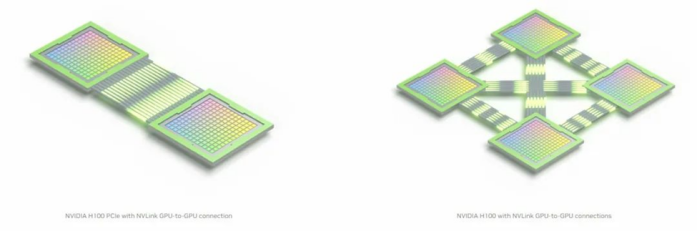
图:PCIe(左)、NVLink协议下的GPU互联
NVLink的首个版本于2014年发布,首次引入了高速GPU互连。
2016年发布的P100搭载了第一代NVLink,提供 160GB/s 的带宽,相当于当时 PCIe 3.0 x16 带宽(双向)的 5 倍。
之后陆续发布了很多新版本,V100搭载的 NVLink2 将带宽提升到300GB/s ,A100搭载了NVLink3带宽为600GB/s。
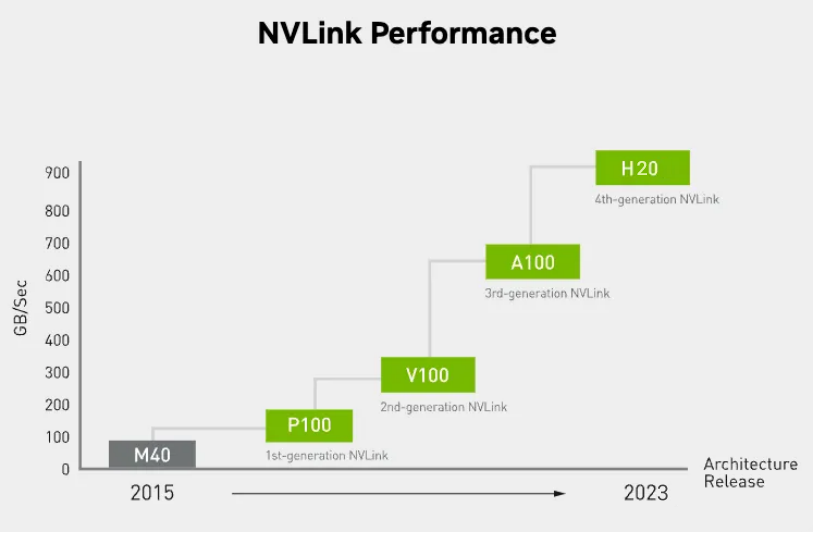


与PCIe 相比,NVLink明显的优势就是高带宽和低延迟,我们先来看看他们的速度对比。传统的PCIe5.0x16规格下互联速度为128GB每秒,而第四代NVLink的规格下,直接达到900GB每秒,也就是PCIe的7倍多(参考下图)。

另外,为了更直观地区别他们之间的数据传输差距,从下图可以看出,传统的PCIe数据交互方式是CPU与GPU之间的数据交互,图中可以看出带宽非常的细窄,而NVLink的交互方式直接绕开了CPU,通过GPU和GPU直连的方式进行数据交互,传输的通道非常地宽敞。
如果对于注重GPU之间数据通信的大规模训练来说,NVLink无疑是最佳性能选择,这也就是目前NVLink在人工智能领域大行其道的主要原因。虽然NVLink的价格目前不菲,但是综合时间成本和效率对比的话,它的训练效率和性价比还是比PCIe高出很多的。
图:PCIe和NVLink的区别
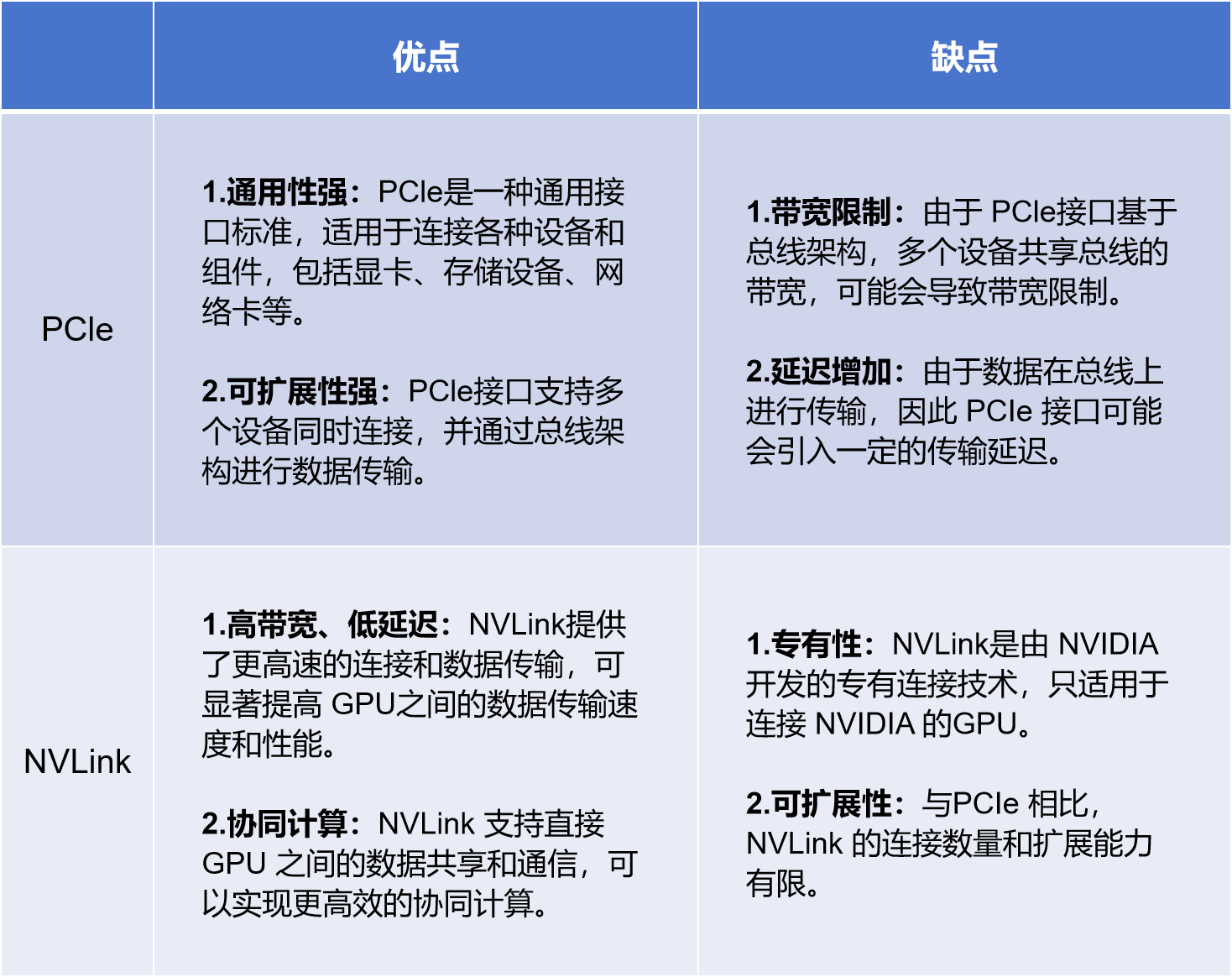
PCIe广泛应用于各种计算机硬件设备,包括显卡、声卡、网卡等。由于其良好的兼容性和扩展性,PCIe已成为计算机系统中不可或缺的一部分。
NVLink主要用于高性能计算和数据中心领域,特别是在需要将多个GPU连接在一起以加速计算任务的应用中。NVLink的高带宽和低延迟特性使其成为此类应用的理想选择。

擎天系列L20 AI服务器是超擎数智国内首发的 NVIDIA 新一代L20 AI服务器,基于 Intel 最新Eagle Stream平台,搭载 NVIDIA L20 GPU,4U8卡 PCIe,采用“283”方案设计,搭载2颗Intel第四代CPU,连接8片L20 GPU、2片CX7 400G NDR网卡和1片BlueField-3 2X200G DPU卡,可满足训练和推理、生成式人工智能、图形视觉计算、视频加速应用等各种AI 业务应用需求。
锋锐系列L20 AI服务器采用 AMD EPYC 9004 处理器,搭载 NVIDIA L20 GPU,2U4卡 PCIe,采用“142”方案设计,搭载一颗 AMD EPYC 9004 处理器,连接4片L20 GPU、2片CX7 400G NDR网卡,并支持多达4个双槽主动或被动GPU可扩展配置,还可以选择 NVIDIA NVLink® Bridge 来实现性能扩展及更高带宽,助力加速AI 和高性能计算 (HPC)工作负载。
元景系列H20 AI服务器是超擎数智推出的智能算力旗舰新产品,搭载 NVIDIA H20 GPU,6U8卡 NVLink,是基于全新一代 AI 超融合架构平台,面向超大规模数据中心的强劲性能,极致扩展的AI服务器,最强算力密度6U空间内搭载2颗Intel第四代CPU,1块 NVIDIA Hopper 架构 HGX-8GPU 模组,系统支持4.0Tbps网络带宽,满足万亿级参数超大模型并行训练需求。

公众号


电话

需求反馈
