


















咨询服务热线:400-0698-860
电话:027-5972 8168
邮箱:info@chaoqing-i.com
总部:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼
北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911





随着人工智能技术的迅猛发展,AI模型在各行各业的应用越来越广泛,从医疗诊断到智能制造,AI正以惊人的速度改变我们的生活方式。然而,如何高效地将这些AI模型从实验室推向实际生产环境,成为了许多企业面临的重大挑战。针对这一痛点,超擎AI平台应运而生。它不仅提供了强大的模型推理部署能力,更为企业的AI应用落地保驾护航。通过超擎AI平台,企业可以轻松实现从模型训练到推理部署的无缝衔接,加速AI成果的转化与应用。
模型的使用离不开推理,推理过程不仅是AI模型产生实际价值的关键环节,更是决定用户体验和应用效果的核心因素。超擎AI平台通过优化推理流程,确保模型能够以最快的速度和最高的精度响应用户请求。通过多种推理引擎的兼容性与无缝集成,超擎AI平台大大降低了模型部署的复杂度。开发者可以轻松将训练好的模型部署到平台上,快速上线并进行实时推理。同时,平台还支持自动化的推理优化机制,根据具体的使用场景调整推理策略,从而达到最佳的性能表现。这使得超擎AI平台不仅是技术专家的得力助手,也是企业推动AI应用落地的理想选择。
特色功能
在超擎AI平台上,你可以轻松地使用经过自己训练和微调的模型进行推理服务部署。无论是自研模型,还是从其他来源下载的预训练模型,都可以通过平台的统一接口进行快速集成和部署。平台支持多种框架,帮助用户高效地在不同的推理环境中运行定制化的模型,实现多样化的AI应用场景。
为了方便开发者和企业用户的集成,超擎AI平台提供了标准的OpenAI API接口。通过这一标准接口,用户可以在平台上将自己的模型转换为标准API进行调用。这种统一的接口不仅简化了开发流程,还降低了系统集成的复杂度,让AI模型的部署和调用更加便捷和高效。
传统推理服务部署模式使用单一服务配置固定计算资源,资源无法复用或快速增加。线上服务初始化计算资源配额为固定值,无法根据资源是使用情况(利用率、使用周期等)进行动态调整,已经分配的计算资源(或计算节点/服务器)不能为其他服务使用。
• 通过平台设置,Requests(请求低峰期):GPU*1;Limits(请求高峰期):GPU*5。
• 能够基于 QPS(请求量)的变化主动为服务提供所需的计算资源,释放过程同样无需手动操作。
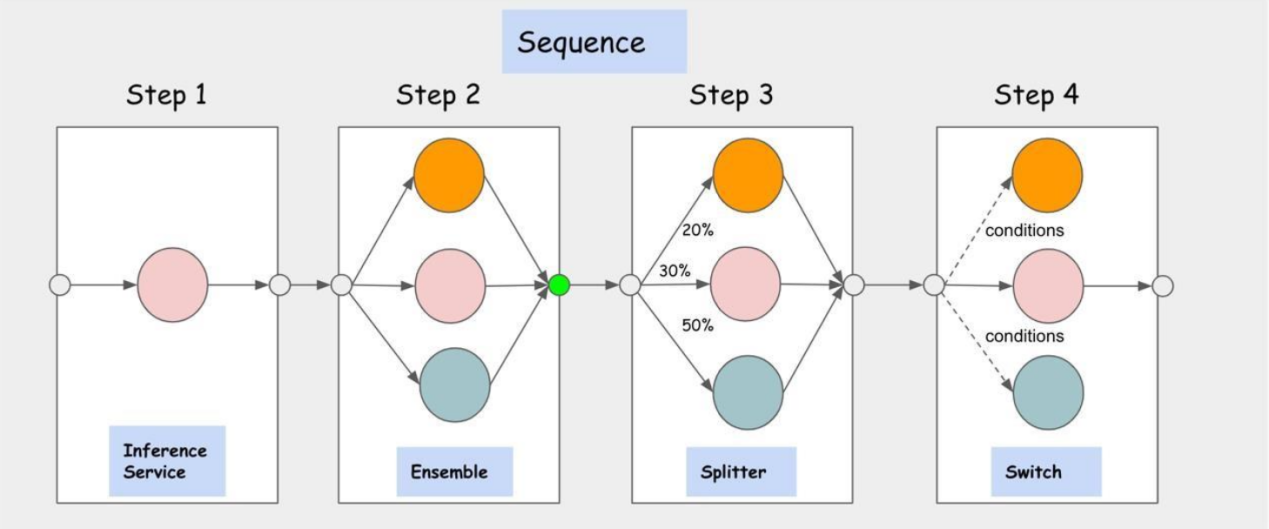
• 多模型推理服务编排:支持串行、并行、条件、合并等编排模式,支持模式的实时修改。
示例一:使用API接口对模型进行调用
1.使用下载的chatglm3-6B模型并将模型发布

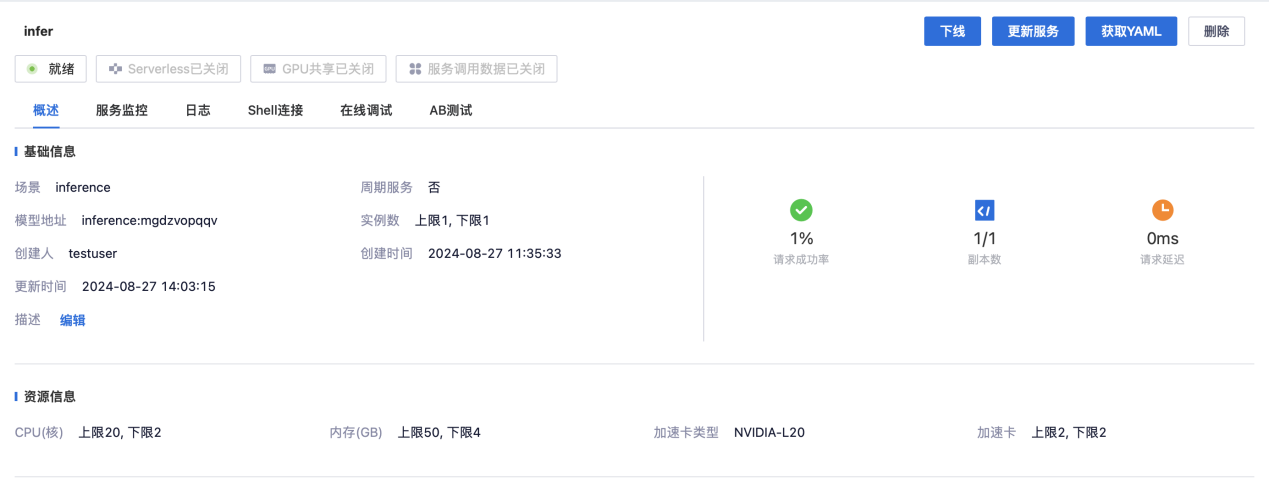
2.调用模型,部署推理服务
3.通过URL请求测试


支持使用OpenAI API请求访问,支持内部调用,以及外部通过域名解析进行访问。不仅能够加快系统的集成和部署速度,还能大幅度提高与其他应用的兼容性与互操作性,使得各类应用能够更方便、更快速地接入并落地,显著缩短开发与上线周期。
示例二:在平台所集成的Chat应用直接进行对话
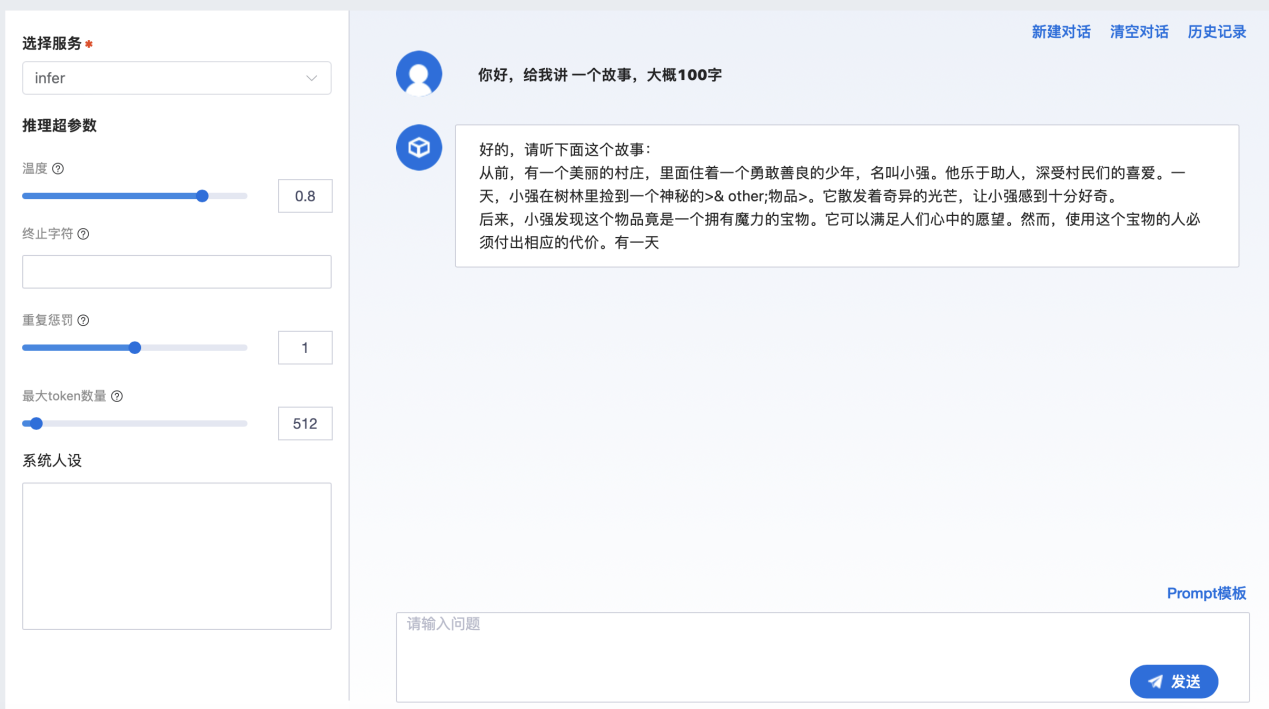
Chat应用支持温度调整,角色设定,Prompt模版导入以及对话记录加载等功能,模型体验更快一步。
在当前AI技术飞速发展的时代,超擎AI平台凭借其强大的自定义模型使用、标准化的OpenAI API接口、自动扩缩容和推理服务编排等特色功能,为企业和开发者提供了高效、灵活的解决方案。未来,我们将持续优化平台功能,不断推动AI技术的普及与创新。无论是在智能制造、智慧城市,还是在金融科技等领域,搭配超擎AI服务器,超擎AI平台都将成为您不可或缺的技术伙伴。

公众号


电话

需求反馈
