


















咨询服务热线:400-0698-860
电话:027-5972 8168
邮箱:info@chaoqing-i.com
总部:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼
北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911





近年来越来越多的行业开始探索大语言模型的应用,比如政务、医疗、交通、导购等行业。通义系列、GPT 系列、LLama 系列等模型,在语言交互场景下表现十分抢眼。以 Gemini 为代表这类大模型甚至发展出了视觉和听觉,朝着智能体的方向演化。他们在多个指标上展现的能力甚至已经超过了人类。然而,大型语言模型也存在诸多不足:
知识的局限性:模型知识的广度获取严重依赖于训练数据集的广度,目前市面上大多数的大模型的训练集来源于网络公开数据集,对于一些内部数据、特定领域或高度专业化的知识,无从学习。
知识的滞后性:模型知识的获取是通过使用训练数据集训练获取的,模型训练后产生的一些新知识,模型是无法学习的,而大模型训练成本极高,不可能经常为了弥补知识而进行模型训练。
幻觉问题:所有的 AI 模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
为了解决纯参数化模型的局限,语言模型可以采取半参数化方法,将非参数化的语料库数据库与参数化模型相结合。这种方法被称为 RAG(Retrieval-Augmented Generation)。
RAG简介
通常一个RAG应用由两部分组成:索引;检索和生成。
索引
从源中提取数据并对其进行索引的管道。这通常是离线进行的。
从原始数据到得到答案最常见的完整序列如下:
存储:我们需要一个地方来存储和索引我们的拆分,以便以后可以搜索它们。这通常使用 VectorStore 和 Embeddings 模型来完成。

检索和生成
实际的 RAG 链在运行时接受用户查询并从索引中检索相关数据,然后将其传递给模型。
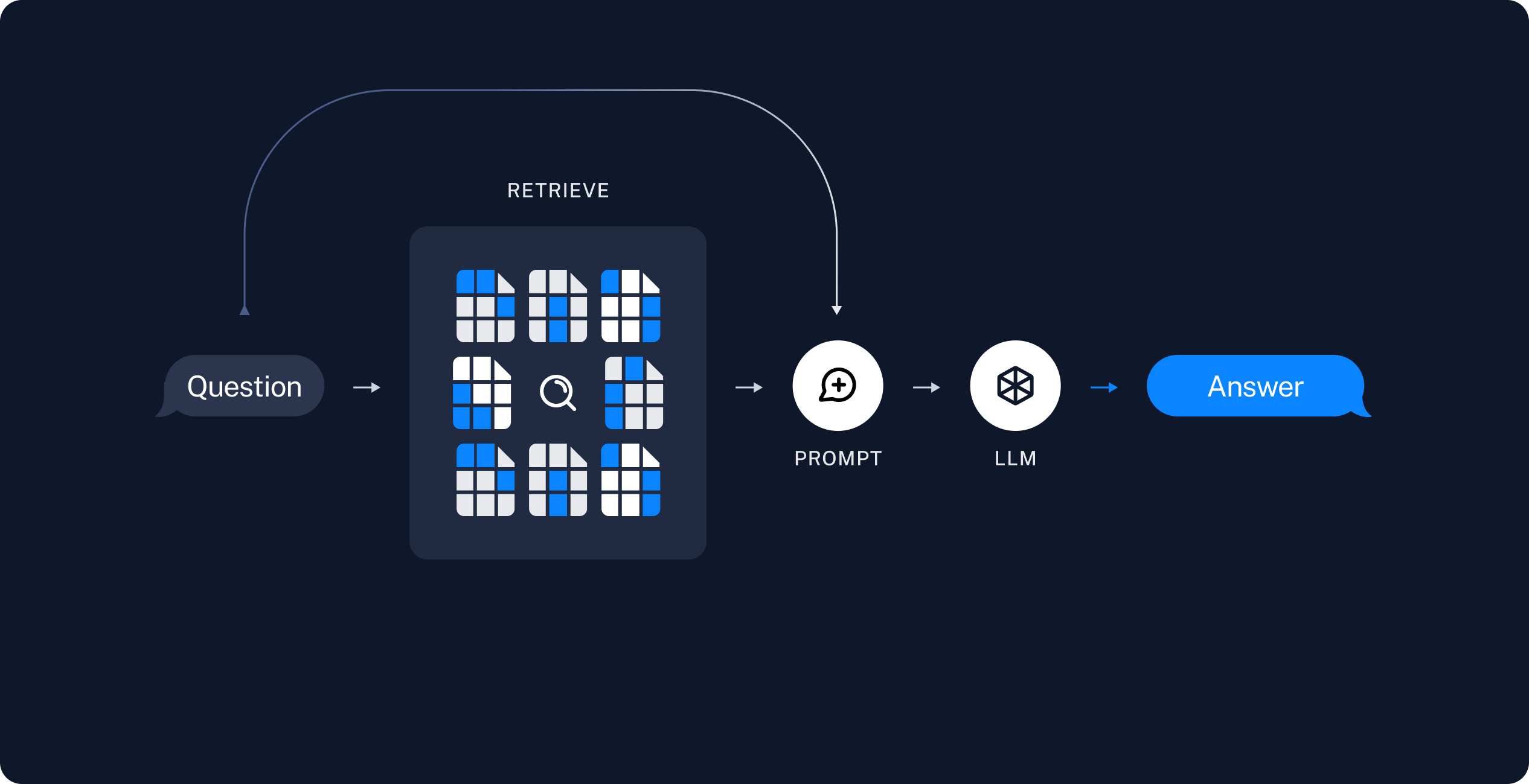
使用超擎AI平台搭建RAG应用
在上篇文章中我们介绍了如何在超擎AI平台部署模型推理服务,接下来我们将通过一个示例展示如何结合平台快速构建一个RAG应用。LangChain是一个常用于开发基于大语言模型应用的框架。在示例中我们将使用LangChain结合Gradio来展示我们的对话应用界面。
软件平台:超擎AI平台

这里我们使用超擎AI平台的安装手册
2.拆分

使用LangChain中的TokenTextSplitter组件进行拆分
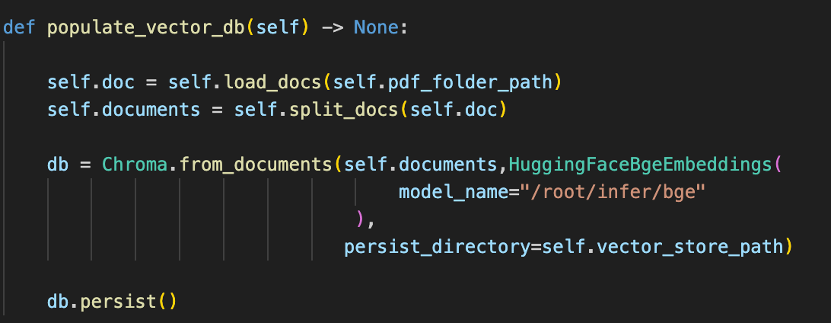
使用ChromaDB向量数据库存储文档信息,使用bge-large-zh-v1.5作为嵌入模型
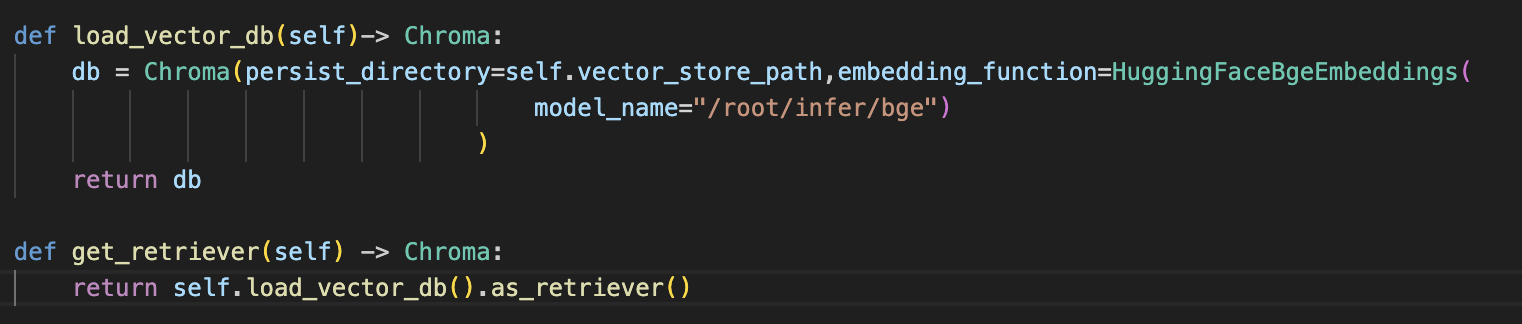
加载向量数据库并使用嵌入模型进行检索返回相关内容
5.生成
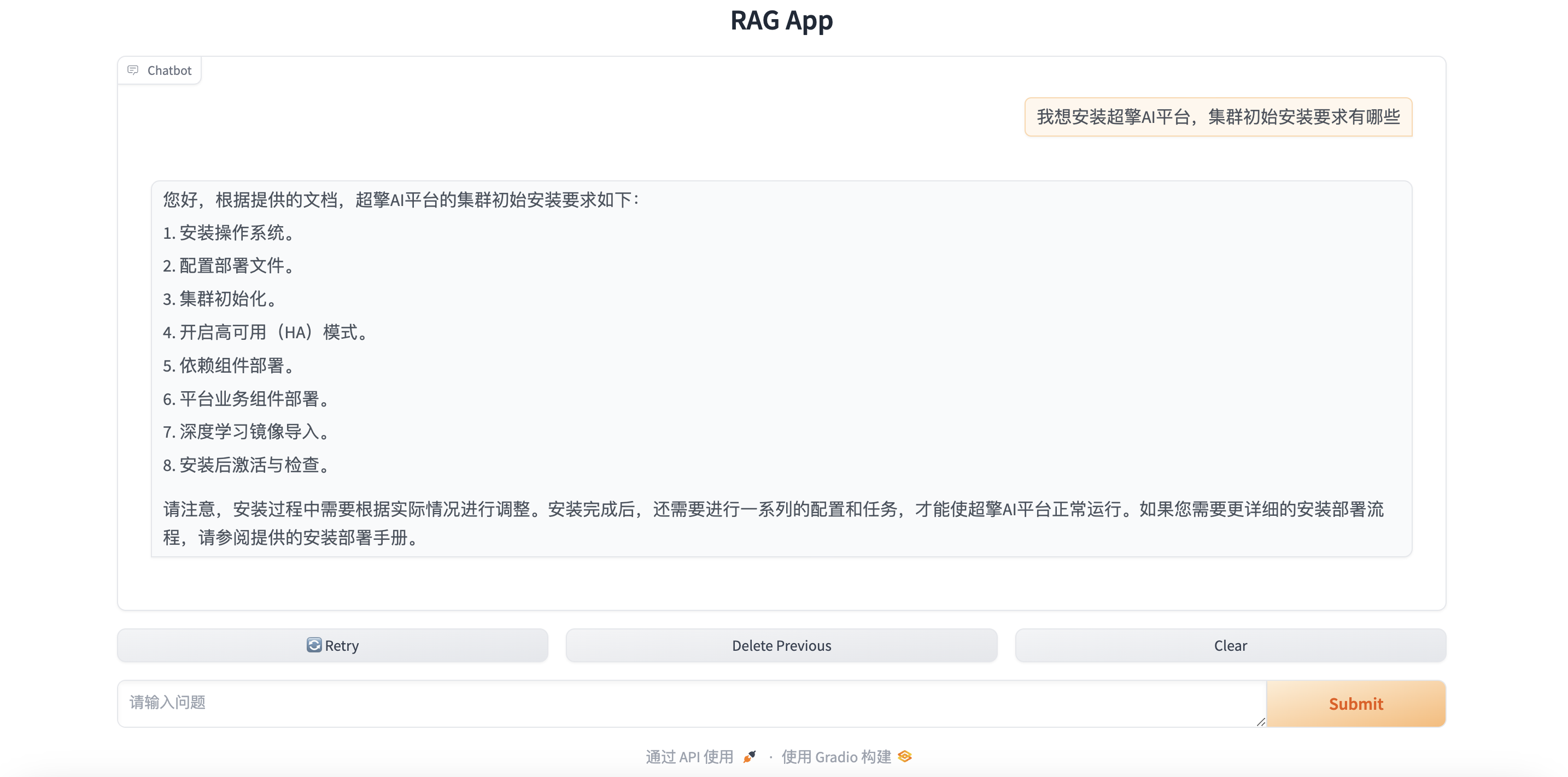
通过超擎AI平台与LangChain、Gradio等工具的结合,我们能够快速搭建起基于大语言模型的RAG应用,充分利用超擎数智平台在计算和管理上的强大优势,实现了数据的高效检索与生成。在未来,随着超擎AI平台的持续发展,企业可以更加灵活、低成本地构建出适应自身需求的智能应用,推动业务的智能化升级。超擎AI平台不仅解决了大语言模型在知识获取和数据安全性方面的挑战,也为更多行业探索人工智能应用提供了坚实的技术支撑。

公众号


电话

需求反馈
