






















咨询服务热线:400-0698-860
电话:027-5972 8168
邮箱:info@chaoqing-i.com
总部:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼
北京运营中心:北京市海淀区北三环西路99号西海国际中心1号楼907(分部)
上海:上海市徐汇区龙爱路27号506(分部)





在当今快速发展的人工智能领域,模型的微调( Fine-Tuning)已成为推动技术落地的重要环节。作为一种通过少量特定领域数据优化大规模预训练模型的方法,微调不仅能够提升模型在特定任务上的表现,还能大大节省训练成本和时间。超擎AI平台以其强大的计算能力和灵活的定制化服务,正在成为帮助企业和科研机构实现高效模型微调的理想选择。在本文中,我们将深 入探讨如何利用超擎AI平台对模型进行微调,并展示其在实际应用中的优势和价值。
1. 模型训练支持弹性任务
超擎AI平台支持深度学习弹性训练任务。相对于一般训练任务,弹性任务能够动态感知资源,自动进行任务的扩缩容,提供更高的资源使用效率和加速模型迭代。用户提交训练任务时,可以选择当前任务是否设置为弹性任务,指定训练支持的最小和最大的资源规格。当前弹性任务支持 Horovod Tensorflow、Horovod Pytorch、Pytorch DDP。
2. 调度系统
调度系统为开发环境、训练任务和推理服务提供资源分配能力,在大规模的群内,选择合适的主机用于运行任务,在提高集群资源利用率的同时,尽可能的提高任务的运行性能,调度器的主要功能主要包括以下几点:
在大模型的调优策略中,模型微调是一个关键步骤。它存在两种策略:
1. 全参数微调(Full Parameter Fine-Tuning)涉及到调整模型的所有权重,使之适应特定领域或任务,这样的策略适用于拥有大量与任务高度相关的训练数据的情况。
2. 部分参数微调(Sparse Fine-Tuning)则是只选择性地更新模型中的某些权重,特别是当我们需要保持大部分预训练知识时,这种方法能减少过拟合的风险,并提高训练效率。
微调的核心效果是:在保留模型泛化能力的同时,提升其在某一特定任务上的表现。
超擎AI平台提供了两种方式来进行模型微调任务部署,用户可以根据自己的需求进行使用
1.一键部署微调任务
平台集成了DeepSpeed框架,可视化设置参数、快速部署框架支持的LLM模型微调任务
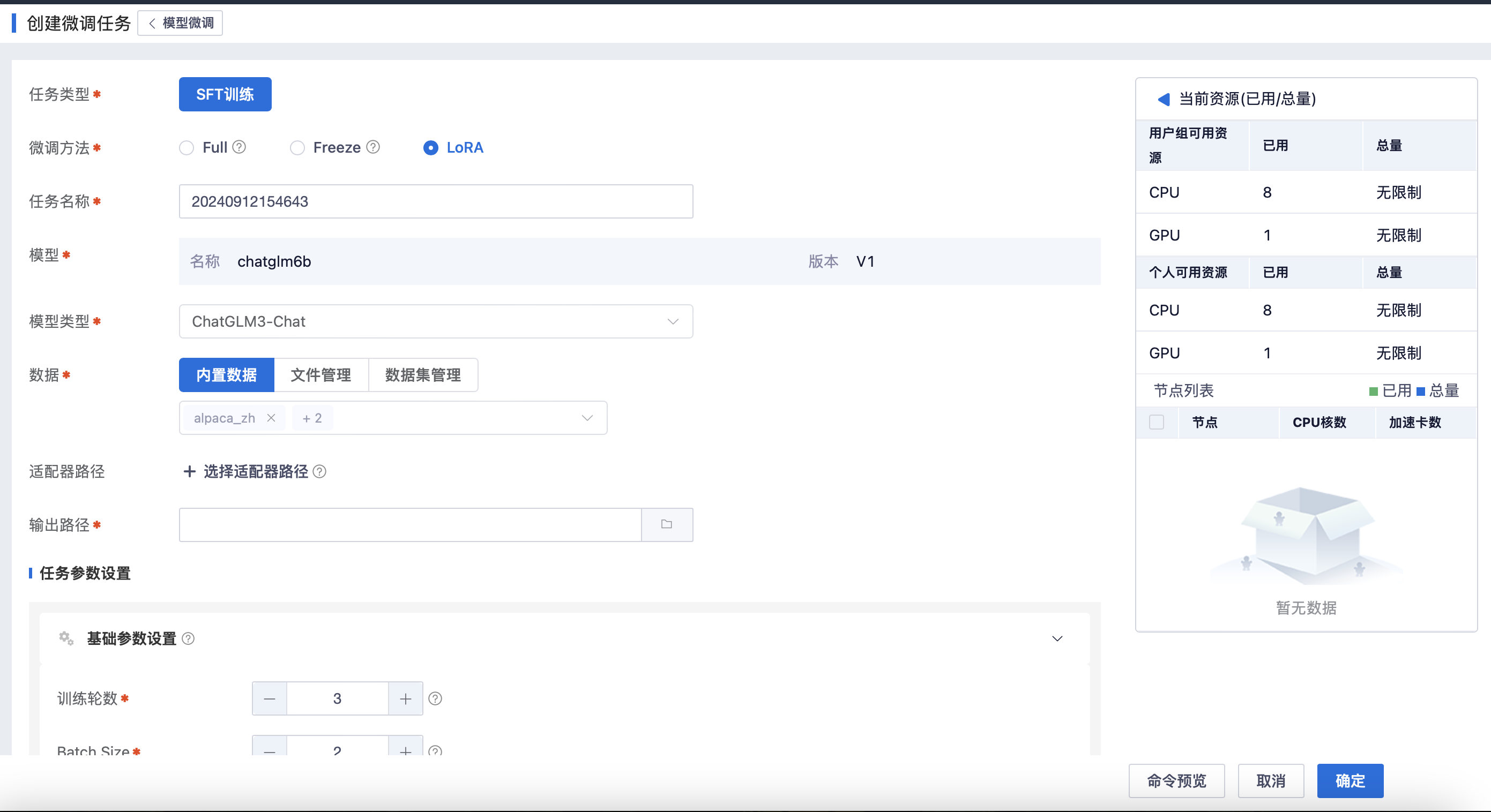
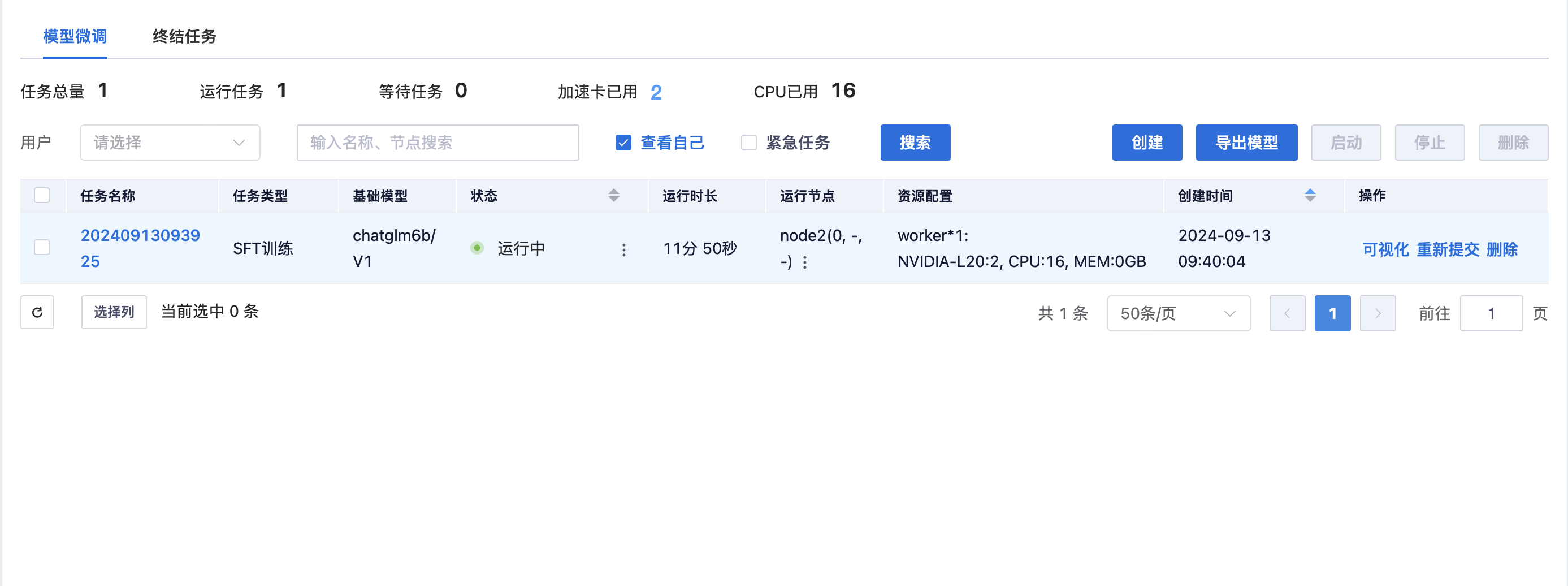
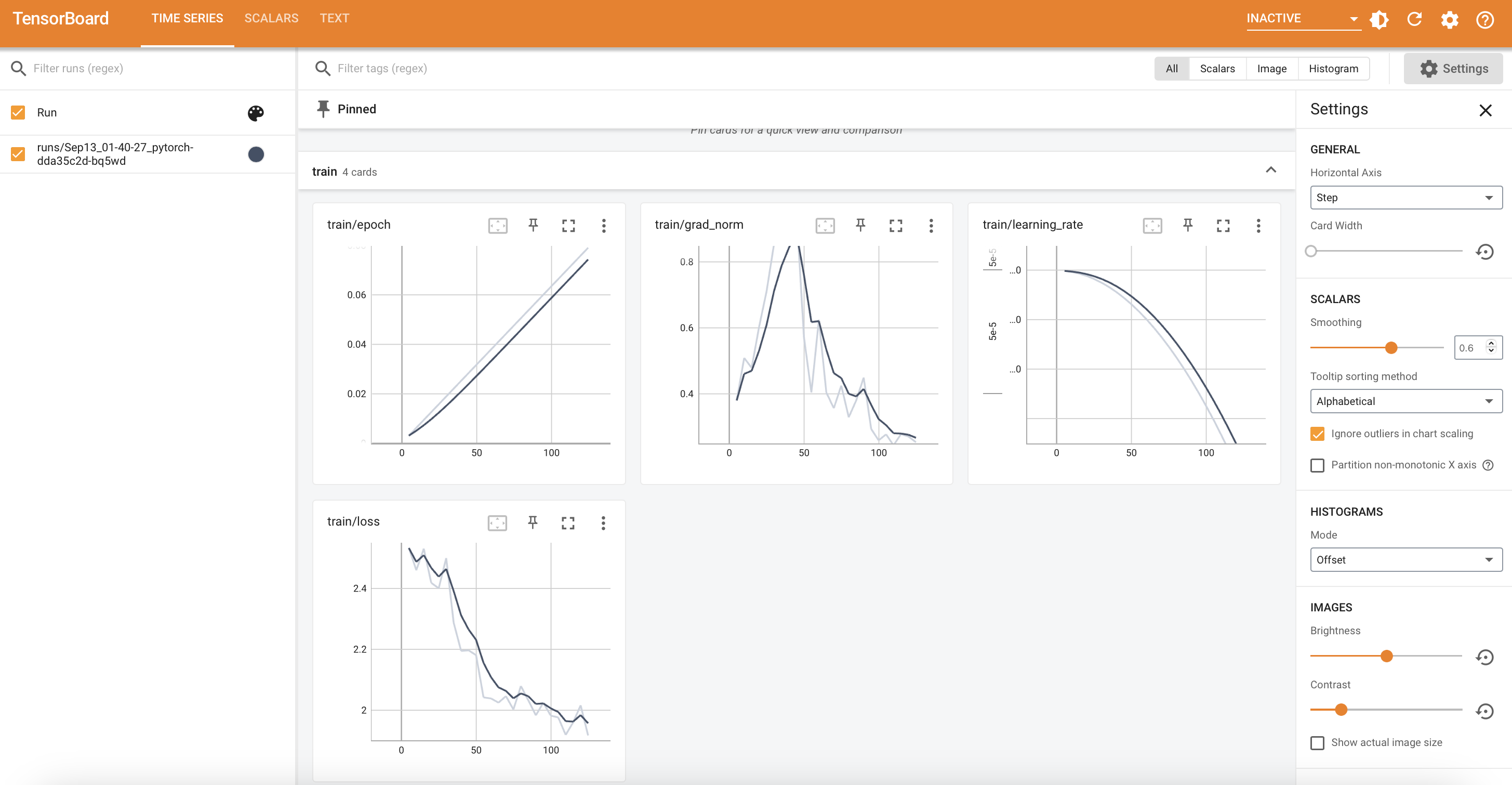
平台内置TensorBoard等可视化工具,实时监控训练状态
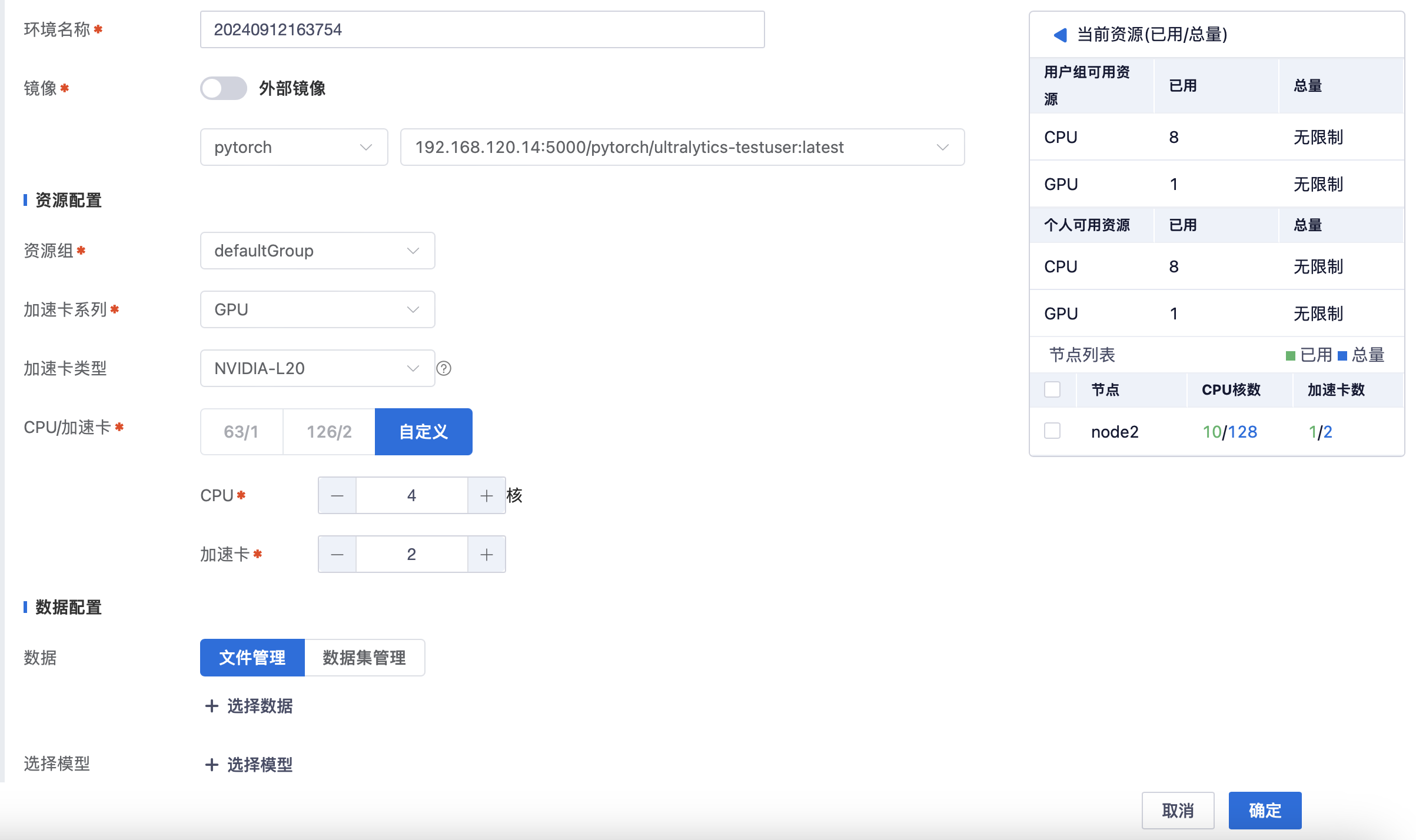
2.创建自定义开发环境部署微调任务
平台支持用户创建自定义开发环境,以适应具体需求。通过个性化配置,用户可以更高效地进行模型训练、调试,提升整体开发效率。
选择合适的镜像以及所需的开发资源。

使用网页shell终端,ssh,JupyterLab三种方式对环境进行访问。
这里选择使用YOLOv8模型在超擎数智锋锐系列4卡L20 AI服务器上进行微调测试展示。
由于YOLO模型在预训练时使用的数据集未包含全面的食物相关内容,我们使用Food-101数据集对其进行微调处理。

使用TensorBoard等可视化工具,实时监控训练状态
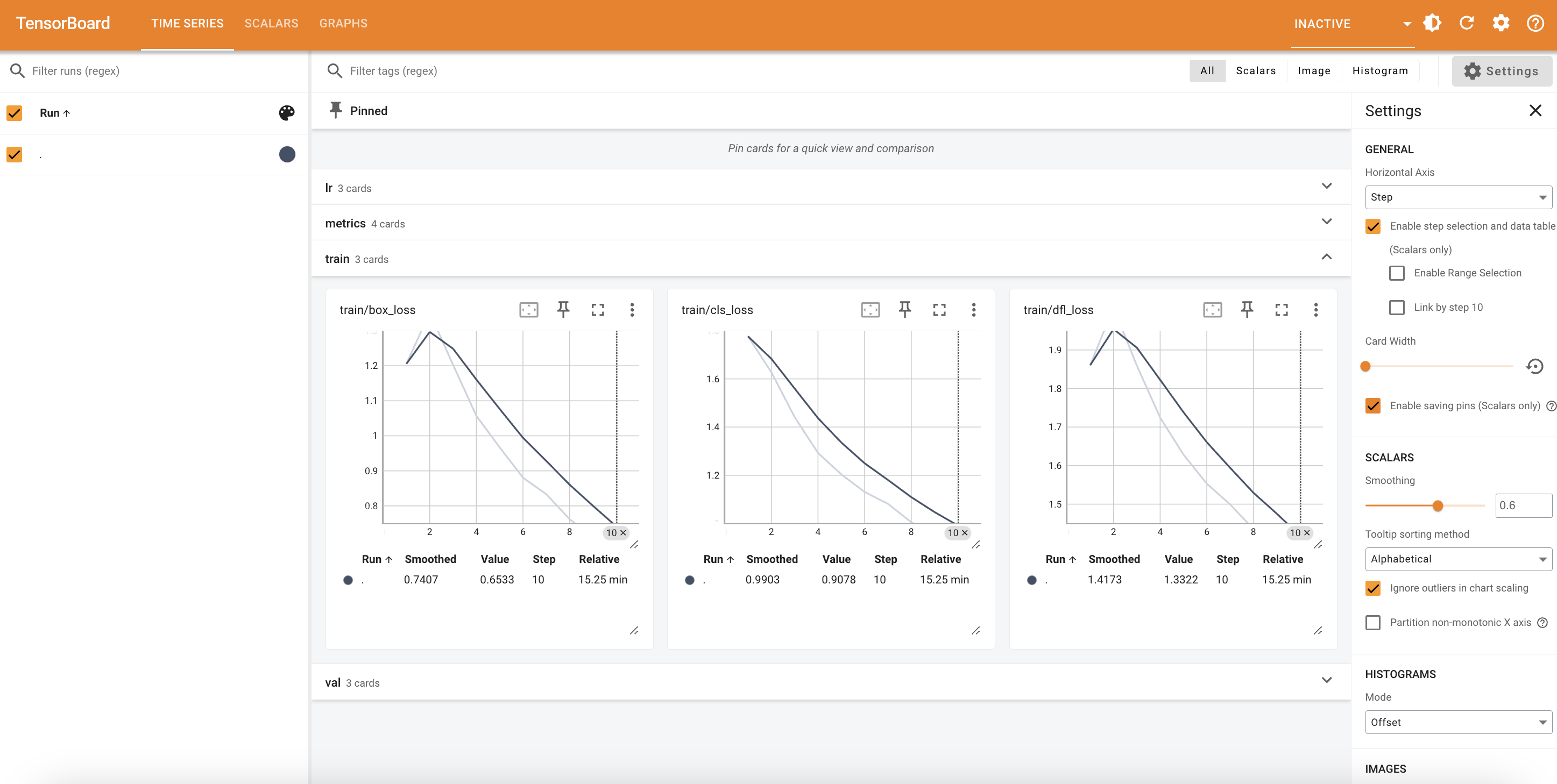
模型微调前后进行推理测试,可以观察到微调后模型在对食物识别方面有显著提升


通过超擎AI平台对模型进行微调,用户不仅能够实现定制化的AI解决方案,还能大大缩短开发周期,提高模型的性能与精度。超擎AI平台的强大功能与灵活架构,让每个开发者都能轻松应对复杂的AI模型优化需求。未来,随着AI技术的不断演进,超擎AI平台将继续扮演推动创新与效率提升的重要角色,帮助开发者在AI领域开辟更加广阔的天地。

公众号


电话

需求反馈
