


















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





本文主要介绍了 FP8 数据格式在大型模型训练中的应用、挑战及最佳实践,展示了 FP8 在提升训练速度和效率方面的潜力和实际效果。
FP8 格式
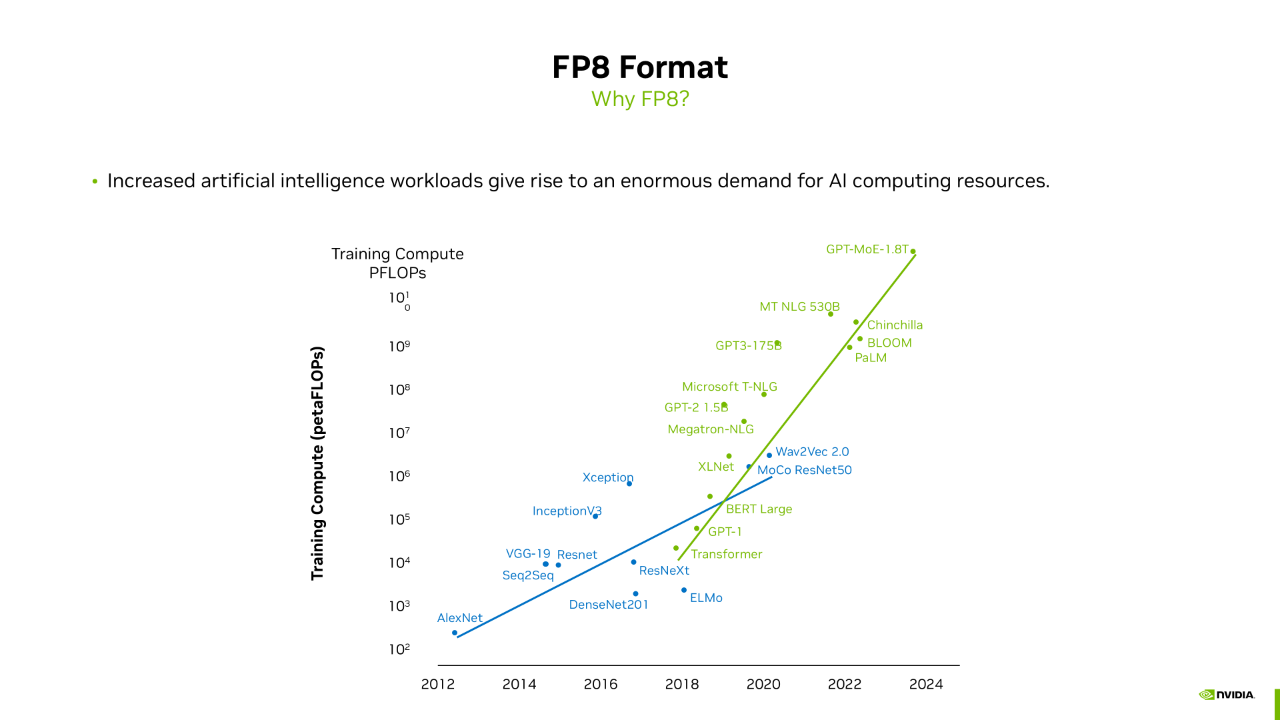
在介绍 FP8 格式之前,我们需要回答一个问题:为什么需要讨论 FP8?从图中可以看出,近年来大模型所需的算力急剧增长,从 GPT-1 到 GPT-3,再到类似 GPT-4 的 GPT MOE 1.8T,算力需求增长了数万倍。这种增长速度的背后是硬件算力的提升。训练过程中的一个重要指标是训练时间。如果训练一个模型需要半年甚至一年,这在实际操作中是不可行的,因为实际训练时间可能是理论值的两到三倍。因此,算力基础设施的提升是大模型迅速发展的基础。
从算力角度来看,近年来 GPU 的单卡算力提升了大约一千倍,这包括工艺制程的改进、硬件结构的优化以及更低的训练精度。随着 FP8 的引入,其 Tensor Core 算力是 FP16 的两倍,为探索更大规模的模型提供了算力支持。
具体来说,FP8 的优势包括:对于计算密集型算子,FP8 的 Tensor Core 相对于 BF16/FP16 能提供两倍的算力,从而大大缩短计算时间;对于 Memory Bound 的算子,FP8 格式所需的数据量更少,可以节省缓存量,加快计算;如果将通信算子中的数据类型也替换成 FP8,也可以获得一定的加速。最后,FP8 训练的模型可以更好地与推理相结合,因为如果模型在训练时的精度是 FP8,那么可以更快地部署到推理侧,而不需要额外的 PTQ 量化过程。
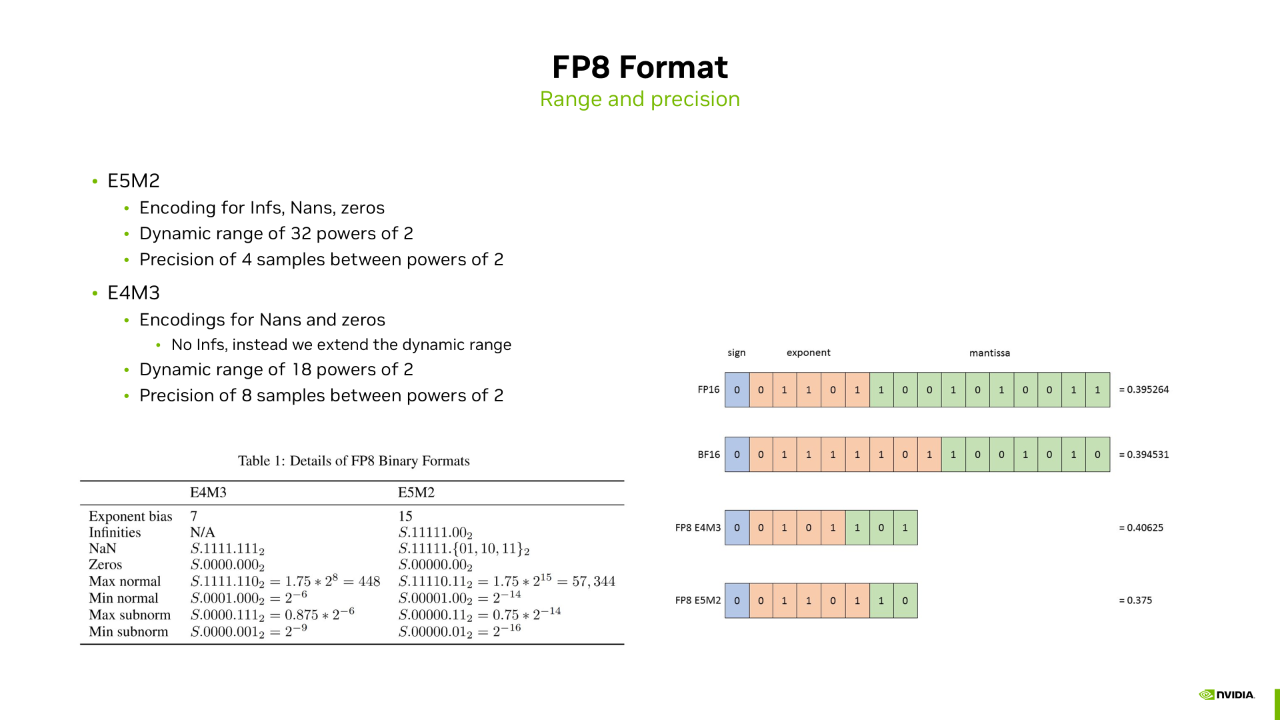
FP8 数据格式包含两种:E5M2 和 E4M3。E 代表指数位,M 代表尾数位。E5M2 包含五个指数位和两个尾数位,而 E4M3 包含四个指数位和三个尾数位。E5M2 由于有更多的指数位,动态范围更大;E4M3 有更多的尾数位,数值精度更好。这两种数据格式在训练时都有各自的应用场景。
在大模型训练中使用 FP8
FP8 带来了更快的训练速度,但也对训练精度提出了挑战。接下来将介绍在大模型训练中如何兼顾模型精度和训练速度。
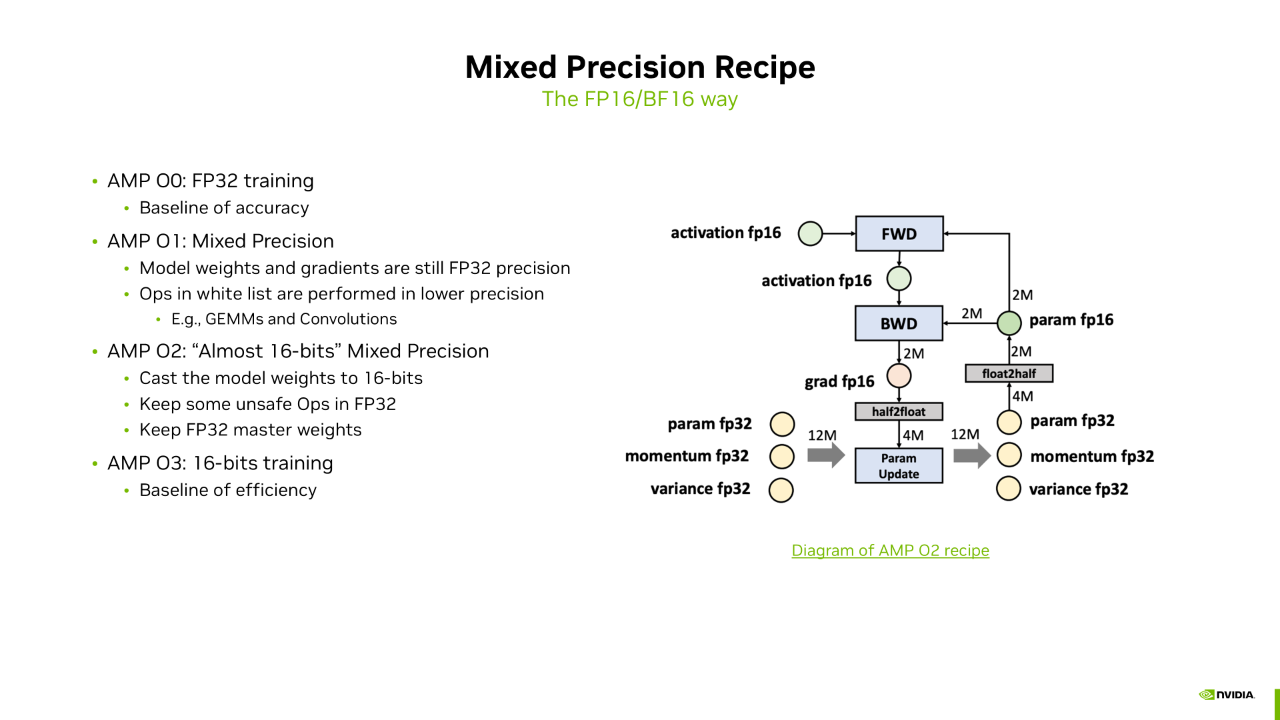
在介绍 FP8 之前,我们先回顾一下 16 位精度训练中如何通过混合精度训练来维持精度。这里列出了四种混合精度训练的方法。第一种和最后一种严格来说不算混合精度,因为第一种是纯 FP32 训练,精度最好;最后一种是纯 16 位精度训练,速度最快。为了兼顾速度和精度,我们列出了额外的两种模式:AMP-O1 和 AMP-O2。AMP-O1 相对于 O0 的不同点在于它会维护一份白名单,白名单中的 OP 会以低精度进行计算,如矩阵乘法和卷积算法,其他算子仍用高精度计算和存储。AMP-O2 方案与 AMP-O3 更接近,不同点在于它会保留一些 unsafe 的 OP,这些 OP 会以 FP32 精度进行存储和计算,如 LayerNorm 和 Softmax 等。此外,还会保留一份 FP32 类型的 Master Weight,因为在模型训练后期,参数更新通常较慢,梯度值较小,容易出现大数加小数的问题,小数被吃掉,所以需要保留一份 FP32 的 Master Weight。目前 16 位精度训练基本上都是采用 AMP-O2 的混合精度方法来训练的。

FP8 训练可以认为是一种 O1+O2 的混合模式。上边这幅图包含了前向和反向计算过程中的一些算子。红色连接线表示高精度数据,绿色连接线表示低精度数据。无论是前向还是反向,整体训练流程的精度仍然是 BF16 的,但会维护一份白名单,白名单中的 OP 以 FP8 精度计算,如 Linear Layer 中的矩阵乘法和 GELU。FP8 的 FMHA 目前在功能上是支持的,但在实际训练过程中通常还是用高精度的 FMHA,以保证更好的收敛性。对于 FP8,我们看到它是以 O1 的模式嵌入 BF16 训练的,BF16 训练本身又是一个 O2 的混合精度方法,所以我们称它为一种 O1+O2 的混合精度模式。
在训练过程中,前向和反向采用了不同的数据精度。前向用 E4M3,因为前向时数值的动态范围变化不大,用 E4M3 提供更好的精度;反向的梯度需要更大的动态范围,所以反向用 E5M2 数据格式。这个流程图中,蓝色框表示从 BF16 到 FP8 的 Cast 过程。这个过程不像 FP32 到 BF16 那样简单直接。
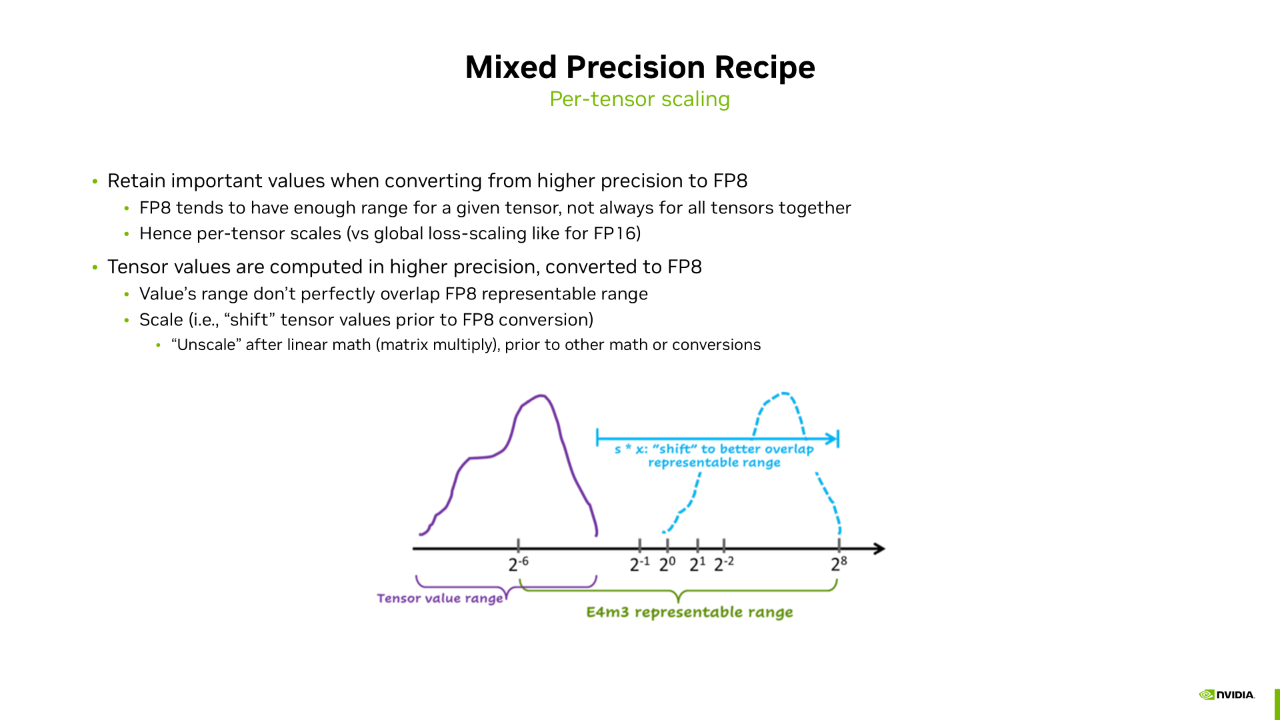
接下来将详细介绍 Cast 过程是如何实现的。因为 FP8 只有 4 位或 5 位指数位,小于 BF16,所以我们为了避免溢出的情况,在 Cast 过程中需要做量化。因为 FP8 的动态范围有限,不足以表示模型的所有 Tensor,所以我们需要做 Per-tensor 的 Scaling。这与 FP16 不同,在 FP16 训练中我们做的是全局的量化。图中形象地表示了 Scaling 的过程。绿色中括号表示 E4M3 的动态范围,能表示 2e-6 到 2e-8 次方范围内的值。紫色中括号表示当前 Tensor 的数值分布。显然,如果将 Tensor 从 BF16 直接转换到 FP8,会有相当一部分值被直接 Flush 为 0,这些信息被丢弃,造成精度损失。我们的处理方式是给 Tensor 乘上一个系数,使 Tensor 的所有值向右平移,直到落到 E4M3 的表达范围内。这样,BF16 类型的 Tensor 就可以比较安全地 Cast 到 FP8。这个就是 Per-tensor Scaling 的过程,这个系数我们称为 Scaling factor。
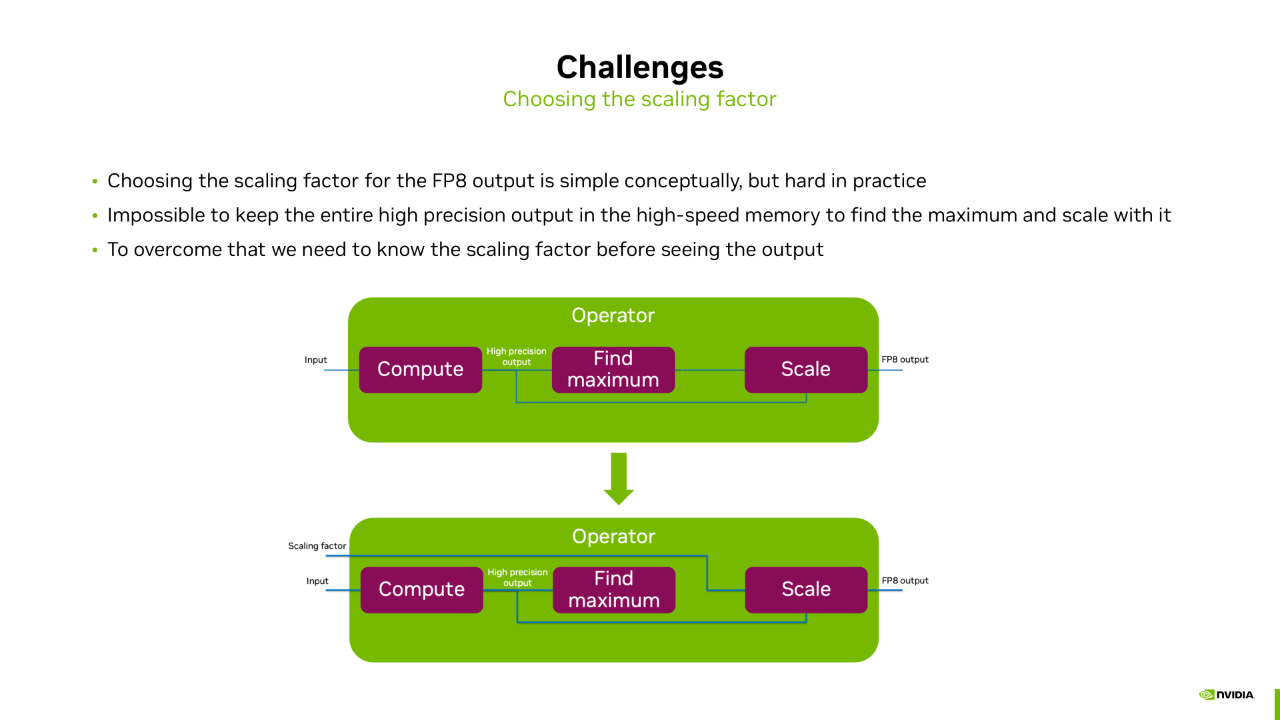
接下来面临的问题是我们怎么来确定 Scaling factor。一种直接的方式是我们在计算得到一个高精度结果之后,通过类似于 torch.max() 这样的一个算子,找到 Tensor 的最大值,通过这个最大值来计算 Scaling factor,然后再量化高精度的 Tensor 为 FP8 的输出。但这种方法的问题是因为 Tensor 的 Shape 通常都会比较大,我们是没有办法把这个 Tensor 全部放到 GPU 的片上缓存 Shared Memory 中的。所以这个过程必须要借助 Global Memory 来进行数据的中转,这就会带来额外的一个访存开销。如果我们能提前知道 Scaling factor 的值,量化过程就可以提前到片上缓存 Shared Memory 中去完成。这时我们不需要等 Find Maximum 的值,Find Maximum 和 Scale 操作可以同时在片上缓存完成,从而避免额外的访存开销。
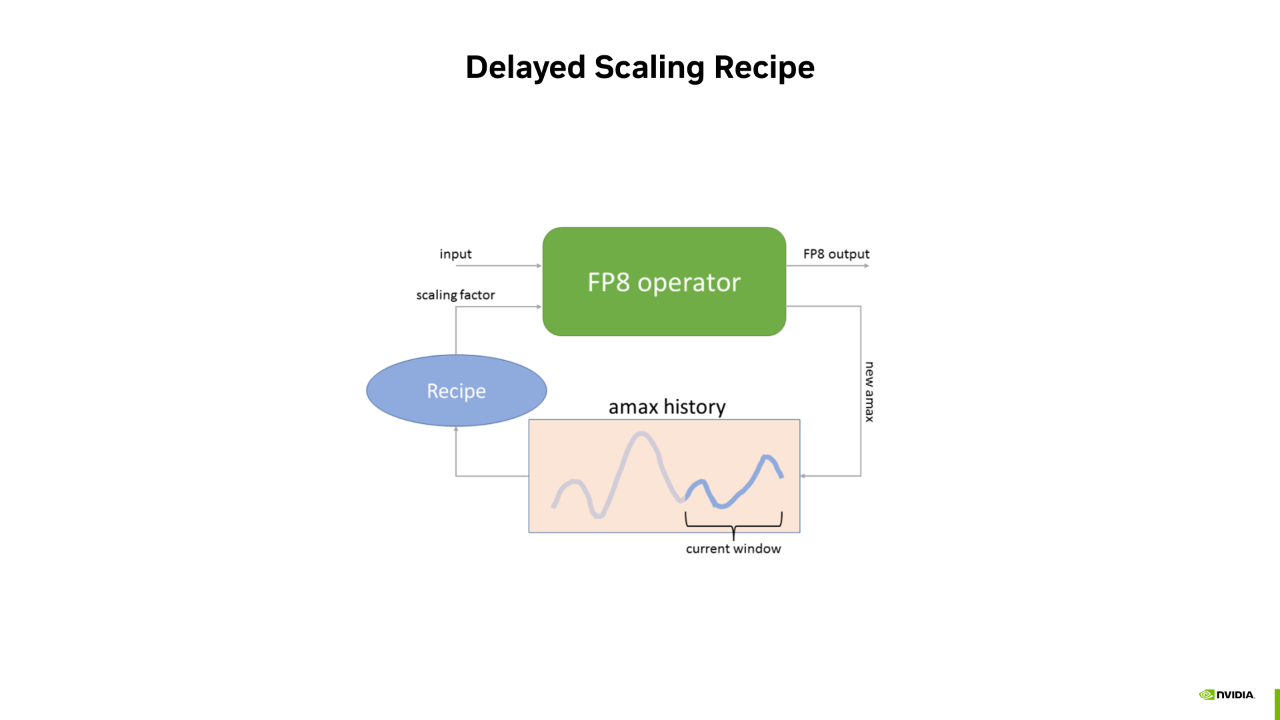
这里我们提前获取 Scaling factor 的方式是 Delayed Scaling Recipe。这种方式的思想是通过当前 Tensor 的历史迭代步信息来估计当前 Tensor 的最大值。
具体的,我们会建立一个 Amax History Buffer,记录一个 Tensor 在历史迭代步中的最大值。当需要当前 Tensor 的 Scaling factor 时,会从 History Buffer 中选出一个最大值,作为当前 Tensor 最大值的估计。有了最大值之后,可以计算 Scaling factor,从而对当前 Tensor 进行 FP8 量化。
另一方面,当要输出 FP8 Tensor 时,我们会统计当前 Tensor 真实的最大值。将真实的最大值 New Amax 追加到 History Buffer 中。因为 History Buffer 是有长度的,所以当新的 Amax 追加到 History Buffer 末尾后,最前面的信息会被丢弃掉。这样,可以一直用最近的历史信息来估计当前 Tensor 的最大值。
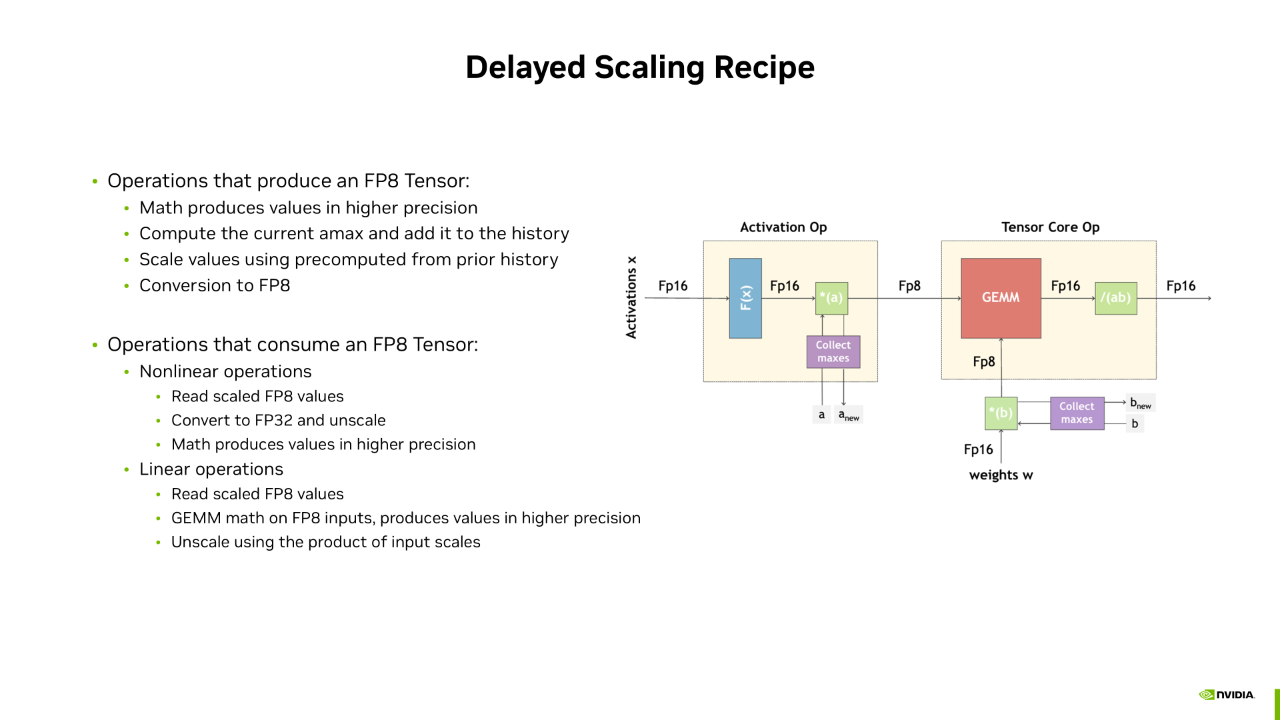
接下来我们把 Delayed Scaling Recipe 过程放到一个真实的场景来介绍它是如何工作的:
图中左边部分是一个 Activation OP,输入是一个高精度的 Activation,输出是一个 FP8 的 Tensor。右边是一个 Tensor Core 的 OP,输入是 FP8 的 Tensor,输出是一个高精度的值。这两个 OP 可以类比到 Transformer Layer 里面的 Layer Norm 和 FC1。对于 Activation OP 来说,它的输入和计算过程都是高精度的。当我们得到一个高精度的结果之后,我们会做两件事:
第一件事,会统计当前 Tensor 的一个最大值,并将其追加到 History Buffer 中。同时另外一件事,我们会从 History Buffer 中选出一个最大值,作为当前 Tensor 最大值的估计,并计算出 Scaling factor,继而将当前的 FP16 类型的 Tensor 量化到 FP8 进行输出。对于 Tensor Core 的 OP 来说,它的 Activation 的输入已经是 FP8 的 Tensor,权重也是用 Delayed Scaling Recipe 的方式来将其量化到 FP8。
这样,我们将 GEMM 的所有的输入都转换成了 FP8,就可以用 FP8 的 Tensor Core 来进行计算,计算的结果是一个高精度的结果。
在输出最终的结果之前,我们需要一个反量化的过程。这是因为 GEMM 的输入对 Activation 和 Weight 都做了量化,所以它的值都被相应的左移或者右移。这就是 Megatron Core 框架里现在集成 FP8 训练的一个方式。
FP8 训练性能

接下来会介绍 FP8 训练的性能结果:
这里使用的软件镜像是 NeMo Framework v24.01。我们可以看到在 Llama 模型上,FP8 训练在训练吞吐上的加速比在 33%-45% 范围内。通过观察 GPU 上的 Nsight System Report,发现 FP8 训练的 Timeline 里面 Kernel 之间很容易出现气泡。这个问题出现的原因是我们将代码中最耗时的矩阵乘 Kernel 换成了 FP8,虽然它的计算时间减半了,但因为 FP8 的 Delayed Scaling Recipe 引入了一些和 Amax 以及 Scaling factor 相关的操作,引入了额外的 Kernel,所以导致 Host 端 launch Kernel 的 overhead 变大。此消彼长,使得 Kernel launch 跟不上 Kernel 计算的速度,产生 Launch bound 的问题。
如何解决 Launch bound 问题,我们将在后续的内容中介绍。
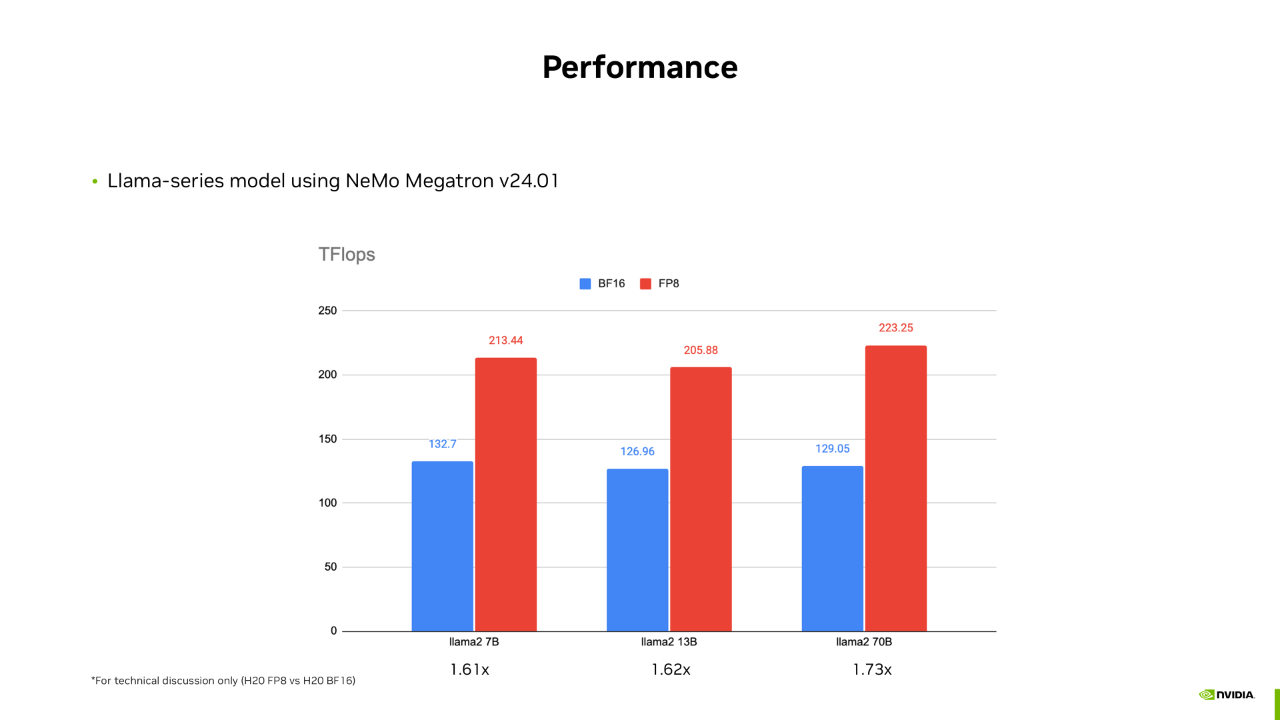
接下来是在另一张 GPU 上的测试结果,同样也是在 Llama 模型上进行预训练,镜像是 NeMo Framework v24.01。可以观察到 FP8 相对于 BF6 的加速比大约是 60%-73%。
最后是 MOE 模型上的一些 Benchmark 结果,模型是 Mixtral 8x7B,软件是基于 Megatron-Core v0.7 开发的 FP8 版本。在这个版本上 ,FP8 的加速比达到了 63%。

再分享下性能上的最佳实践:
FP8 这部分的性能问题并不多,比较常见的是 Kernel 之间的气泡问题。为了解决这个问题,首先我们可以从减小 Host 端 Kernel launch overhead 的角度出发,尽可能地将这些 Kernel fuse 起来,减小 Kernel launch 的次数。比如我们可以将 Amax 以及 Scaling factor 相关的 Kerner fuse 起来,也可以把 Rotary Potential Embedding 这部分的 Kernel fuse 起来,以及 Swiglu 的 Fusion。除此之外,还可以利用 CUDA Graph 来将这些 Kernel 合并为一次 Graph 的 launch,来减小 Kernel launch 的开销。另外,我们在代码中要尽量避免 Host 端与 Device 端同步,这个同步会强制阻塞 Host 端操作,从而加重 Launch bound 问题。我们在平时写代码的过程中用 Torch 的 OP 可能就会不经意引入同步,我们在前向计算完成之后可能会对 Loss 进行一些处理,比如检查一些 NaN 之类的,就会引入 Host 端与 Device 端同步。
最后是关于超参调整的建议:在显存允许的情况下,我们会推荐尝试用更多的 PP 而不是 TP,因为 PP 的通信粒度会更粗一些,引入的 Kernel 会更少。另一方面可以调整训练的超参使得梯度累加的次数变少,当 GPU 的数量和问题规模比如 Global Batch Size 与 Synchronize 不变的情况下,一个 Global Step 的计算量是恒定的,当梯度累加次数越少时,意味着每次梯度累加所分到的计算量就越大。同时,每次梯度累加,Host 端 Kernel launch 的开销是恒定的,所以当 Device 端的计算与 Host 端 launch 的开销的比例达到一定程度,Launch bound 的问题就可以被减轻甚至直接消除掉。
这里关于超参调整的建议是从减小 Kernel 之间气泡的角度出发的,实际在训练过程中做超参调整时,要考虑的因素要更多,要做全盘的考虑。
FP8 训练过程中的收敛性
接下来介绍 FP8 收敛性相关的信息,收敛性的结果我们按照大语言模型训练的不同阶段分别进行介绍:
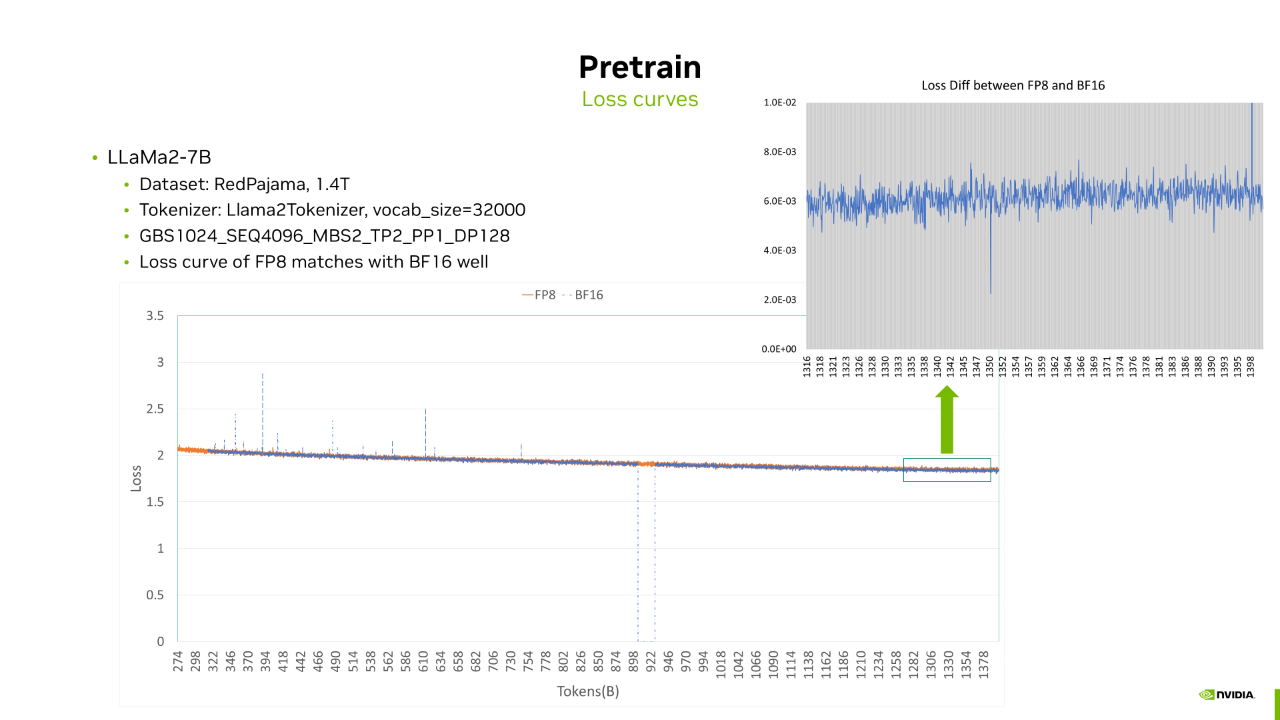
首先是预训练阶段。我们训练了一个模型结构和 Llama2-7B 相同的模型,数据集采用的是开源的 RedPajama,处理之后的数据量是 1.4T Token,超参用的是 TP2_PP1_DP128。
这里给出了从 300B 到 1.4T Token 之间的 Loss 曲线,以及训练末期 FP8 和 BF16 Loss 的差值。
通过这两幅图可以看到 FP8 和 BF16 的 Loss 曲线是很接近的,二者之间 Loss 差值在 10-3量级。
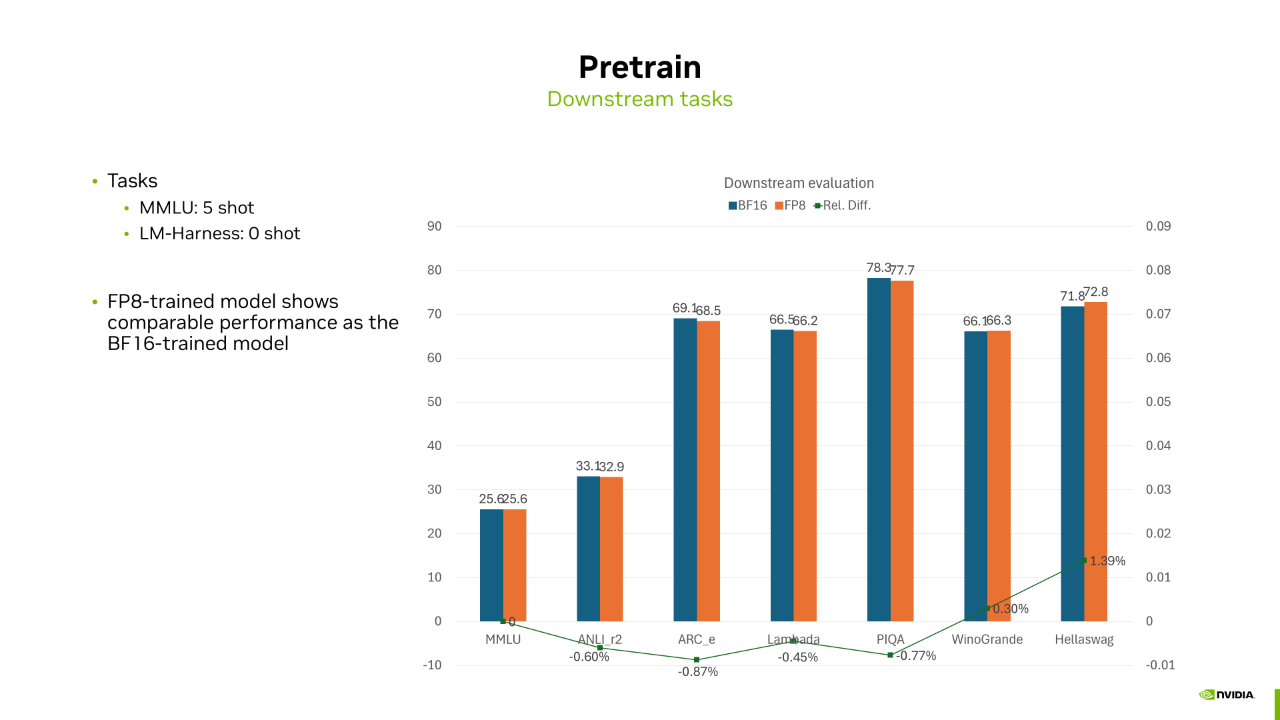
接下来是下游任务的结果,这里选取了 MMLU 和 LM-Harness 等几个任务,对训练好的模型进行评测。
结果显示 FP8 和 BF16 训练的模型在不同任务上的得分会有高低,但总体相差不大。所以,对于预训练来说,FP8 训练的模型无论是 Loss 曲线还是下游任务都可以和 BF16 匹配的很好。
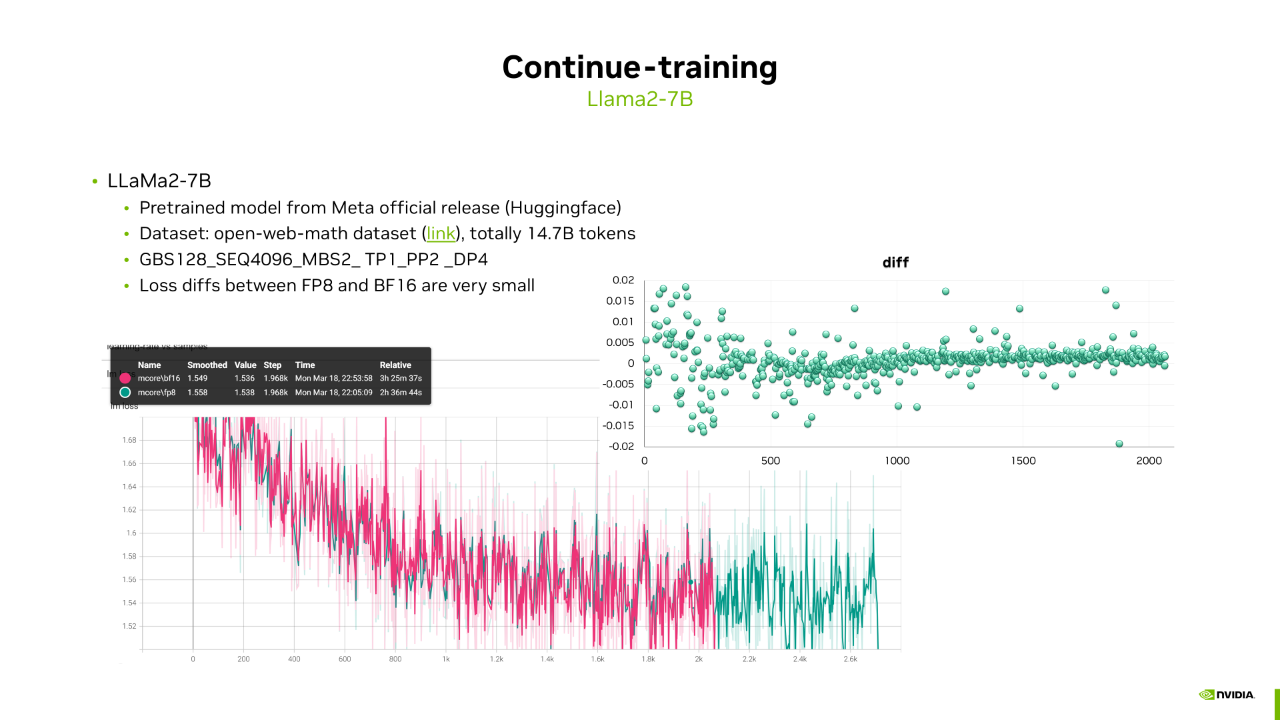
接下来的场景是模型的增量训练,比如从外部获取到一个预训练模型,我们需要给它注入新的知识,对 LLaMa 系列模型添加中文知识等等。我们选择了从 HuggingFace 下载的 Llama2-7B 模型,并使用 Open-Web-Math 数据集进行训练。训练配置包括 TP1_PP2_DP4,我们提供了 FP8 和 BF16 的 Loss 曲线及其差值,可以看到同样它们之间的 Loss 差值也非常小。
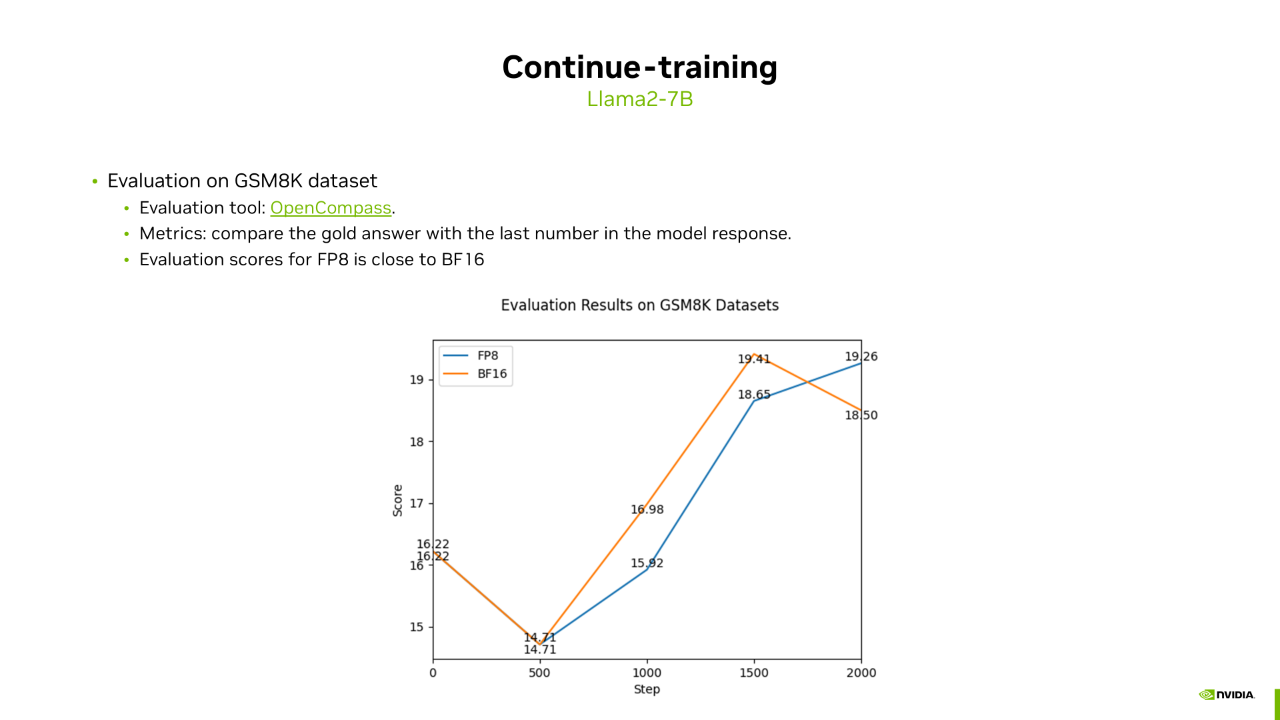
在下游任务评测中,我们选择了 GSM8K 任务,并使用 OpenCompass 工具进行评测。我们每隔 500 步对训练过程进行评分,以追踪下游任务的变化。结果显示,FP8 和 BF16 训练的下游任务得分总体走势一致,且都显示出一定的波动性。两次训练中,FP8 和 BF16 的最高得分相近,表明 FP8 在增量训练场景下的表现与 BF16 类似。

在 SFT(Supervised Fine-Tuning)结果中,我们选择了 Llama2 系列的三个模型,并使用开源的三个数据集混合进行训练。评测任务为 MT-Bench。从 Loss 曲线和下游任务结果来看,这三个模型的 FP8 Loss 曲线和下游任务得分都能与 BF16 对齐,证明了 FP8 在 SFT 训练中的可行性。
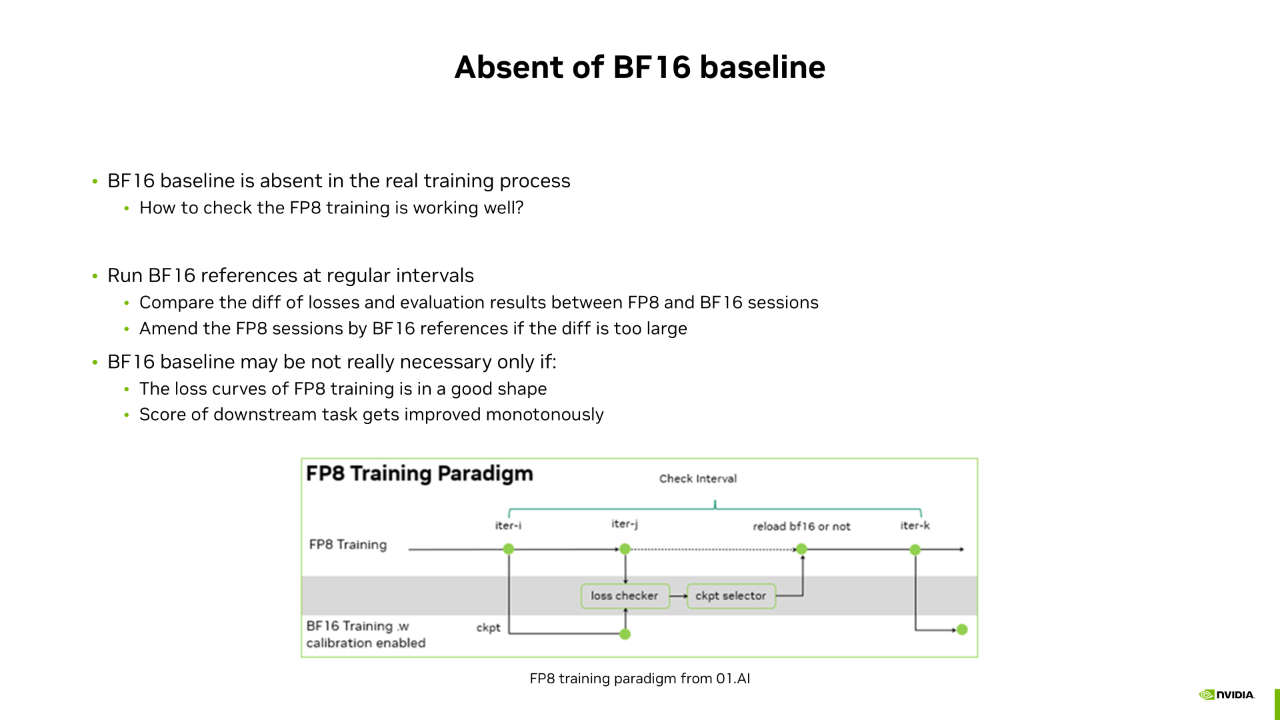
在实际训练过程中,我们没有 BF16 baseline,因此需要通过其他方法判断 FP8 是否处于正确的收敛路径。一种方法是参考 01-AI 的做法,定期用 BF16 跑一定步数(如 100 到 200 步),作为 BF16 reference。通过比较 FP8 和 BF16 reference 的 Loss 曲线及下游任务得分,如果它们接近,则认为 FP8 训练正确。如果差距较大,则用 BF16 替代 FP8 完成该期间的训练。另一种方法是不一定需要 BF16 baseline,只要 FP8 训练的 Loss 曲线持续下降,下游任务得分持续提升,就认为 FP8 处于正确的收敛路径。
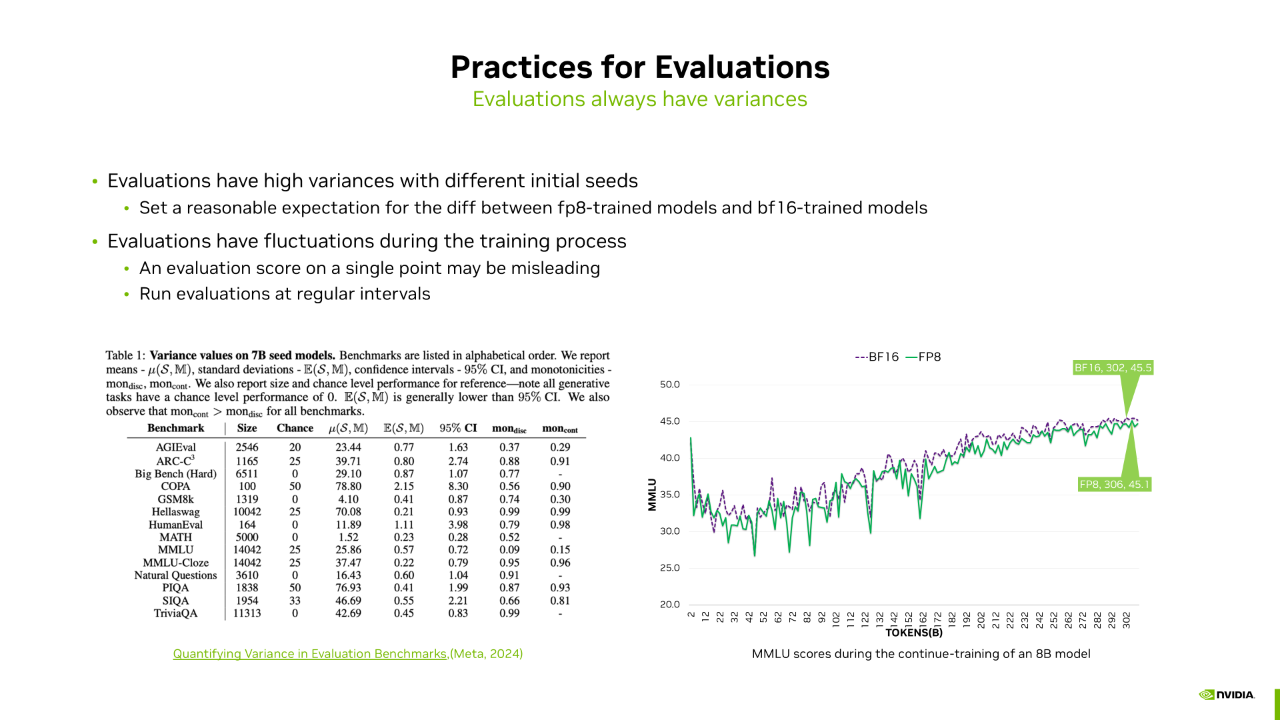
在对比 FP8 和 BF16 的下游任务得分时,应正确看待二者在下游任务上的得分差异。
Meta 最近发表的论文选取了上百个模型,这些模型除了初始化的随机数种子不同外,其他配置和环境相同。论文统计了这些模型在不同下游任务 Benchmark 上的统计值,包括均值、方差、95% 的置信区间及单调性等。从方差及 95% 置信区间来看,不同随机数种子对下游任务得分影响较大。例如,AGIEval 的平均得分是 23.44,95% 置信区间是 1.63,意味着模型得分在 21.8 到 25 之间都是合理的。GSM8K 的平均得分是 4.1,置信区间是 0.87,意味着模型得分在 3.2 到 4.9 之间都是合理的。尽管 FP8 和 BF16 之间的区别与随机数种子的影响不同,但仍有助于设定 FP8 训练的下游任务预期。当 FP8 的下游任务得分落在 BF16 的 95% 置信区间范围内,应认定 FP8 训练的模型与 BF16 匹配。

在收敛性过程中遇到问题的 Debugging Practices,可以将问题分为几类。
首先是非 FP8 的问题,尝试用 BF16 进行 Resume training,如果损失曲线与 FP8 一致,问题可能与 FP8 无关,而是与数据集或其他模块相关。
第二类是软件相关的 Bug,可以尝试最新软件栈或切换到 Transformer Engine/Megatron Core 的最近的几个稳定版进行调试。
第三类是 Scaling factor 的问题,可以尝试更保守的 Recipe,如 just-in-time 的 Scaling factor,如 Current scaling,来消除 Scaling factor 引起的误差。另外,尝试用 BF16 替代 FP8 来定位是哪个 GEMM 引起的问题。
最后是 Evaluation 过程中的问题,FP8 训练的模型用 BF16 推理可能得到偏低分数。因为 FP8 数值格式的原因,一些精度会被丢弃,用 BF16 推理时这些信息会被重新引入,反而成为噪声。对于精度要求高的任务,如 MMLU,会产生较大影响。推荐大家在用 BF16 推理遇到精度问题时不妨试试用 FP8 进行推理。如果训练时的混合精度是 FP8 加 BF16,推理时则不能转为 FP16 精度,因为 FP16 动态范围有限,又没有应用 Per-tensor scaling,容易出现上溢问题,所以需要推理精度仍然保持为 BF16。最后推荐用多点采样的方式避免 Evaluation 过程中的噪声问题。
展望
最后是展望和思考:

除了 Delayed Scaling 外,我们还进行了其他实验,如 Current Scaling 和 Block Scaling。
Current Scaling 使用当前 Tensor 的最大值计算 Scaling factor,再将其 Cast 到 FP8,使用 Just-in-time 的 Scaling factor,对当前 Tensor 有更好的表示,不会出现上溢情况。
除此之外,我们还尝试了更细粒度的 Scaling Recipe,如 Block Scaling 和 Per-channel Scaling,以每个 Block 或每行为一组,计算各自的 Amax 及 Scaling factor,保证不出现上溢情况下,减小下溢比例。因为 FP8 Tensor 附带多组 Scaling factor,常规 FP8 GEMM 不支持这种情况,需要对 FP8 GEMM 进行改造,定制化开发来支持这种情况。
最后回顾下低精度训练的发展过程与思考:
首先大语言模型经历了从 32 位精度训练到 16 位精度训练的转变,遇到了训练不稳定性的问题。各个公司提出了不同解决方案,如 Google 通过跳过一定 Data batch 来消除 Loss spike,Meta 则通过修改 Learning Rate、Weight Decay 及模型结构等来优化。最终发现将数据类型从 FP16 换成 BF16 可以很好地解决这些问题,因为 BF16 具有更大的动态范围,被广泛应用于各大公司的大模型训练上。
现在正在经历 16 位精度到 8 比特精度转化的过程,尝试更稳定的 Scaling Recipe,如 Current Scaling 或 Block Scaling,或通过修改模型结构提高训练稳定性。
总结
我们选择更低精度的出发点是为了加快训练速度,更快的训练速度意味着可以用更多数据训练更大模型,根据 Scaling Law 得到更好模型效果,或者在更短的时间内训练出性能相当的模型。另一方面,低精度训练格式天然对模型训练效果有影响,因此需要找到方法使 FP8 训练在绝大多数 Case 下稳定收敛,达到与高精度训练相近的模型效果。
现在的 Delayed Scaling Recipe 在绝大多数场景下都可以很好的 Work,但仍有改进空间,无论是使用更鲁棒的 Scaling Recipe,还是针对 FP8 训练的特点调整模型结构,NVIDIA 技术团队都在持续探索。无论如何,低精度训练是大模型训练的趋势,NVIDIA 技术团队将持续探索更好的 Scaling Recipe,让大家更好地使用 FP8 训练,相应进展会不定期的分享给大家。

公众号


电话

需求反馈
