



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





随着以ChatGPT等为代表的AI新应用的出现,标志着大算力时代的到来。当前人工智能技术及生态迭代加快,对智能算力提出更强更大规模的需求。作为关键环节与核心底座,以智算中心为代表的智能算力基础设施,在AI落地破局与赋能新型工业化进程中,被赋予更重要的定位,成为支撑人工智能技术及产业发展的重要基石。
算力设计运营服务是超擎数智依托核心技术能力,为客户提供的高价值服务,帮助客户从零开始,构建适合其业务需求的算力系统,从算力集群、存储、智算网络到安全,通过量身打造的最优算力整体方案帮助用户实现算力资源的最大化利用和业务价值的提升,满足用户从大模型训练、推理到人工智能+应用的业务需求和技术挑战。
以建成一个1500P(FP8)智能算力集群及统一智算管理平台项目为例,超擎数智针对用户需求,提供设计、交付、运营、运维端到端服务体系,为客户实现算力价值最大化。
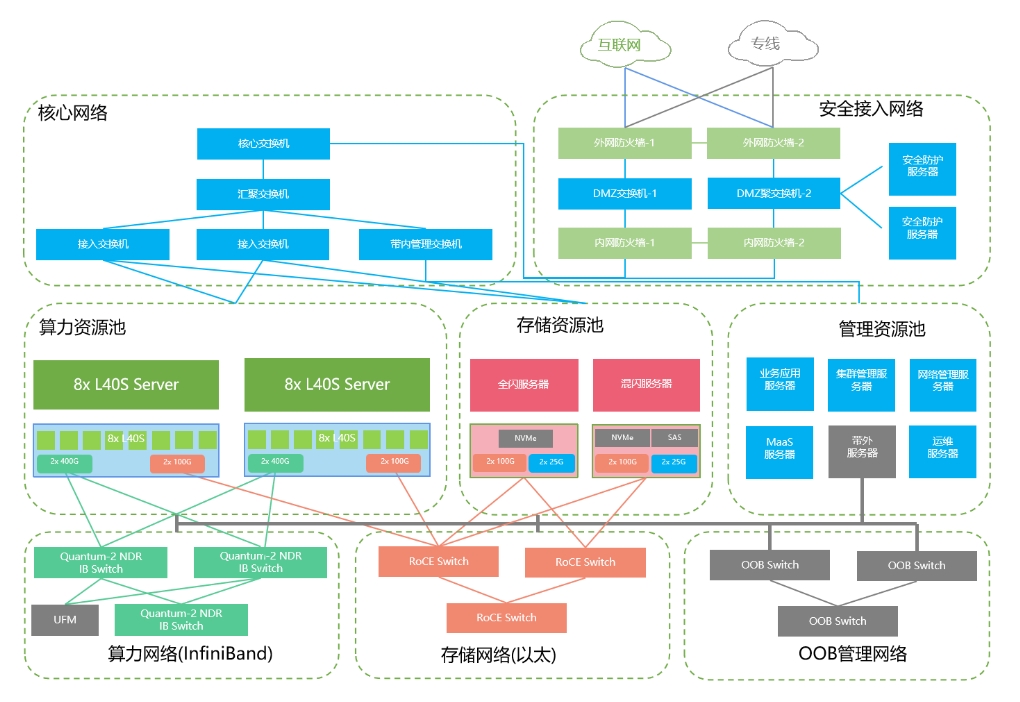
采用等保三级架构,部署边界防火墙、堡垒机、日志审计、漏洞扫描、网络审计、攻击预警、数据库审计等系统。
127台8x L20服务器,提供约250P(FP8)算力
2x 400G IB网卡
高性能存储服务器:全闪500T 提供2x 100G上行
文件存储服务器:混闪4PB 提供2x 100G上行
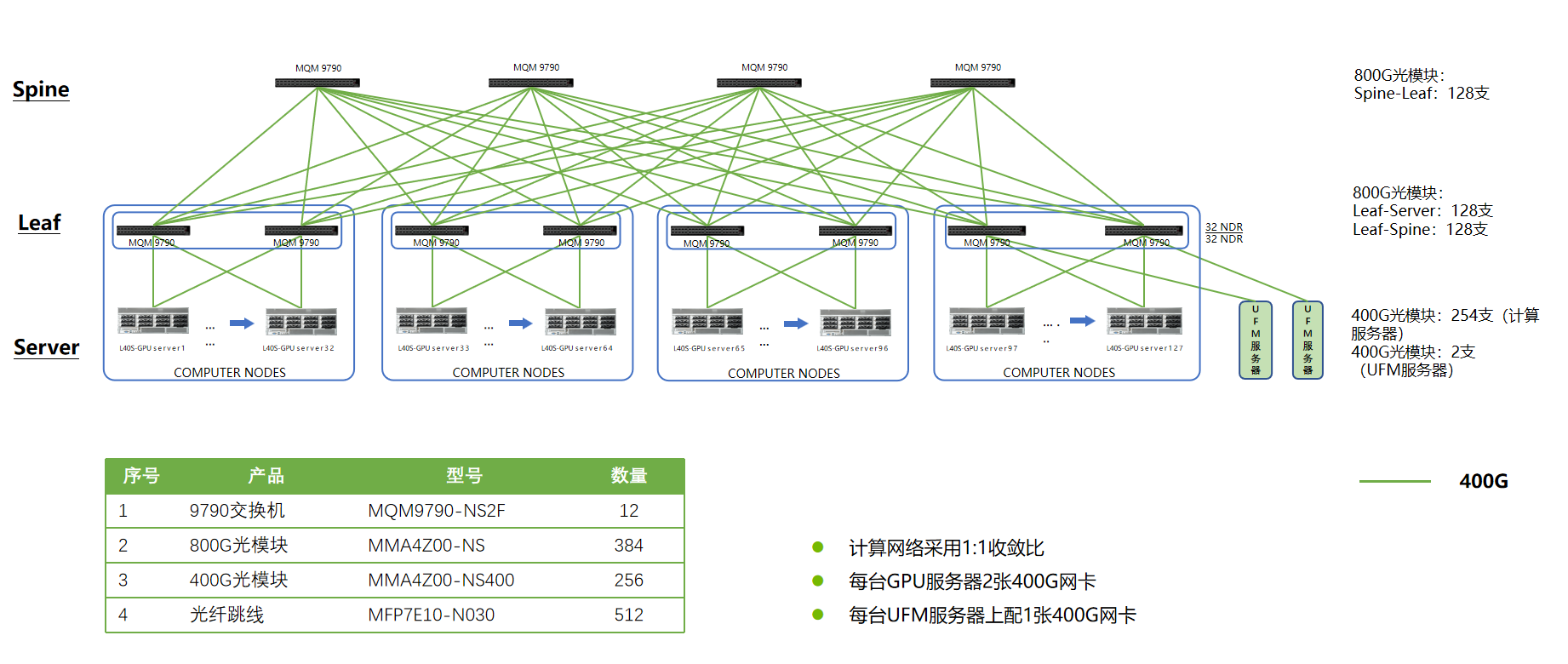
算力网络(InfiniBand):Spine-leaf架构 NDR模块800-400Gbps组网
存储网络(以太): Spine-leaf架构 HDR模块100-100Gbps组网
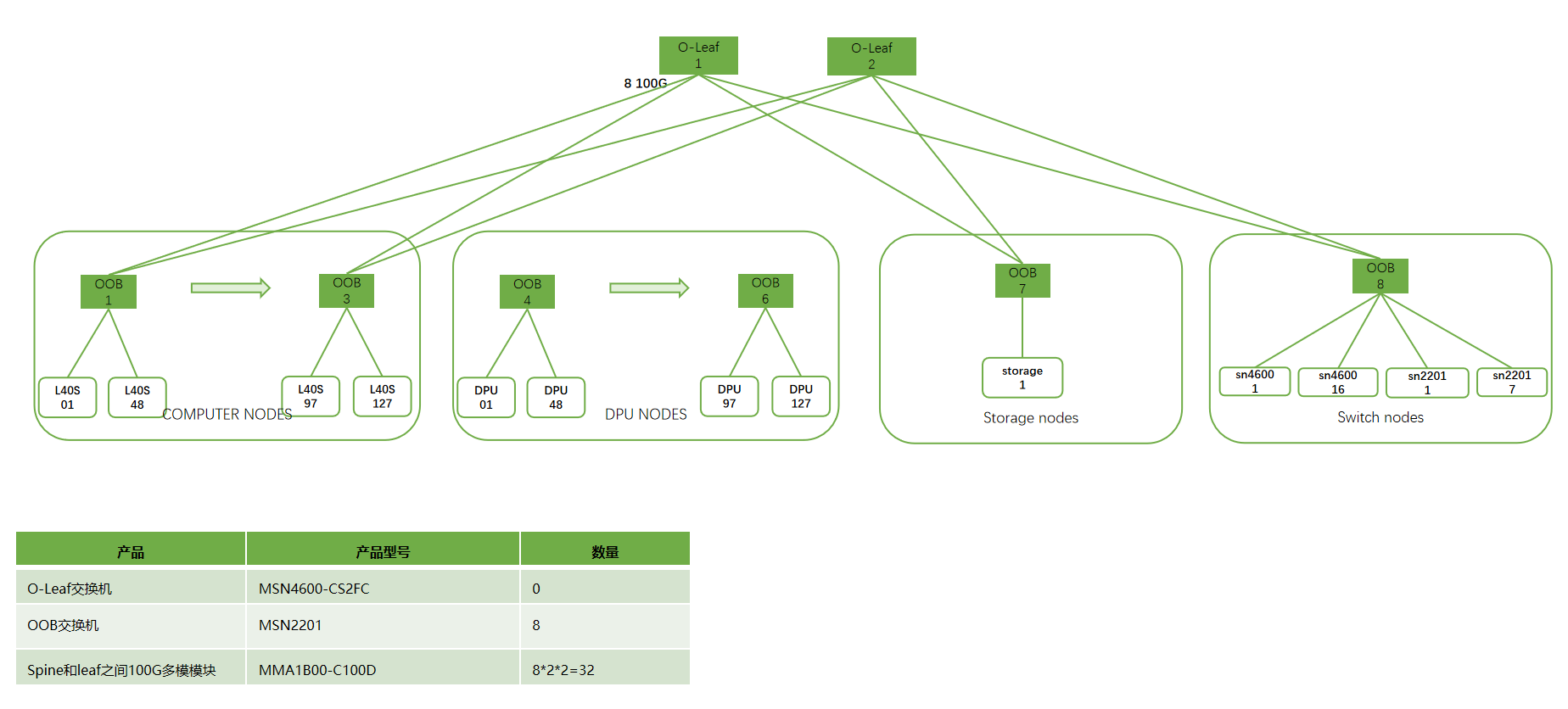
管理网络:带内25G业务管理+OOB带外管理
核心网络:核心汇聚接入交换机
超擎数智自研的擎天、锋锐、元景系列AI服务器产品,为大规模数据训练和推理提供强劲性能,帮助AI用户高效构建AI基础设施和应用环境,满足大模型训练、推理、科学计算、图形视觉计算等AI场景下的多元算力需求,为AI新质生产力提供强劲引擎。



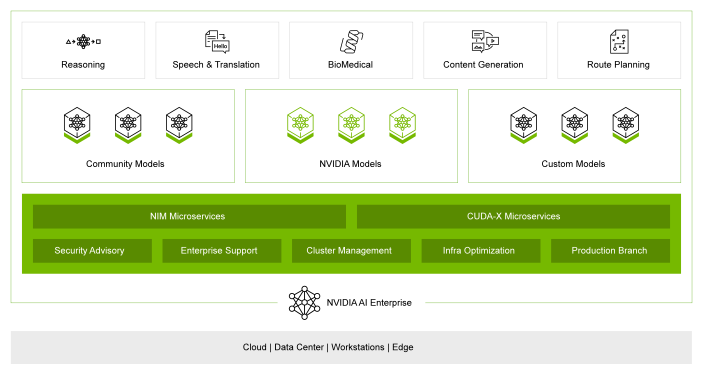
NVIDIA AI Enterprise 是一个端到端云原生软件平台,可加速数据科学工作流,简化生产级协作驾驶和其他生成式 AI 应用的开发和部署。易于使用的微服务优化了模型性能,可提供企业级的安全性、支持服务和稳定性,能够确保以 AI 为基础开展业务的企业从原型到生产的平稳过渡。
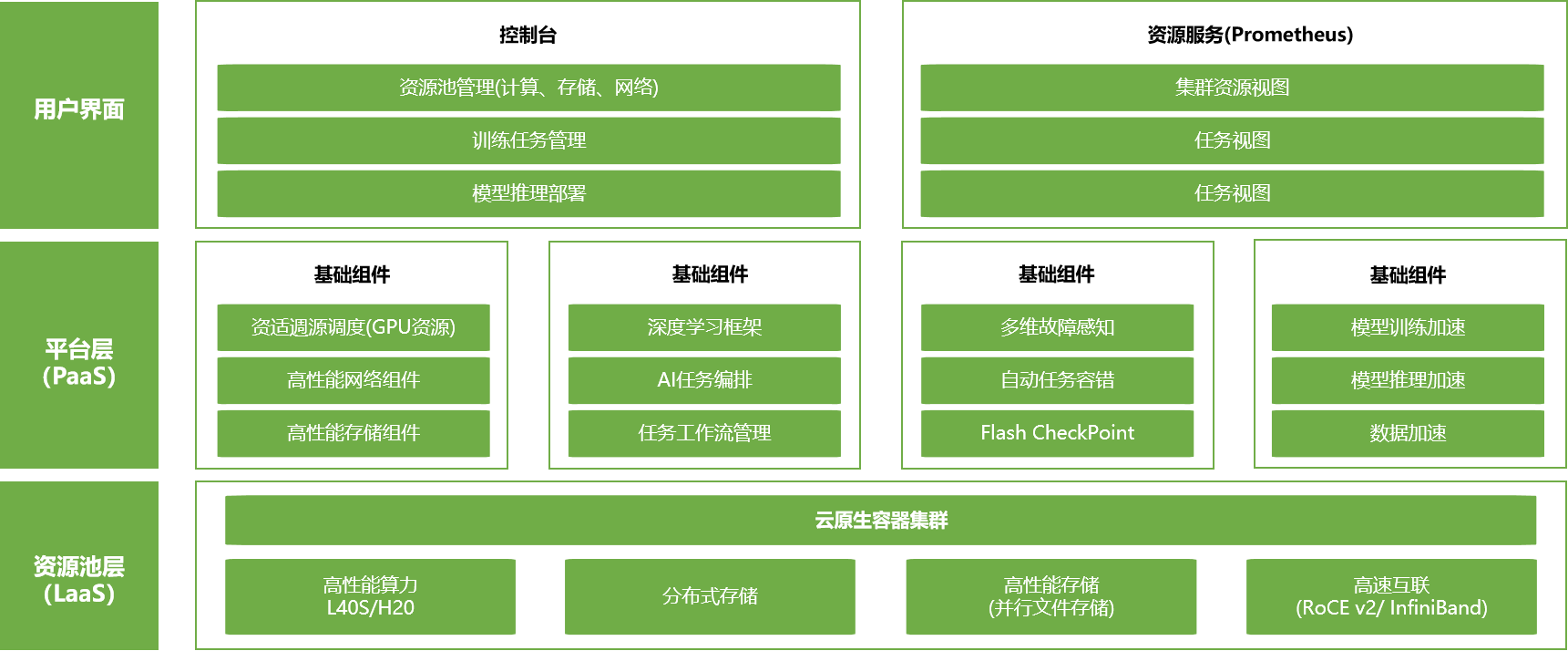
超擎算力调度平台提供全面的管理和优化功能,包括控制台资源池管理(计算、存储、网络),训练任务管理,模型推理部署,以及资源服务(Prometheus)和集群资源视图。平台还具备编排调度深度学习框架的能力,以及任务工作流管理和容错功能,通过多维故障感知和自动任务容错,确保任务的高可用性。平台还支持Flash CheckPoint技术,以及训练和推理加速,以提高效率。在基础设施层面,平台支持云原生容器,以及高性能算力和分布式存储。高速互联支持(ROCE v2/ InfiniBand)确保了数据传输的高效性。
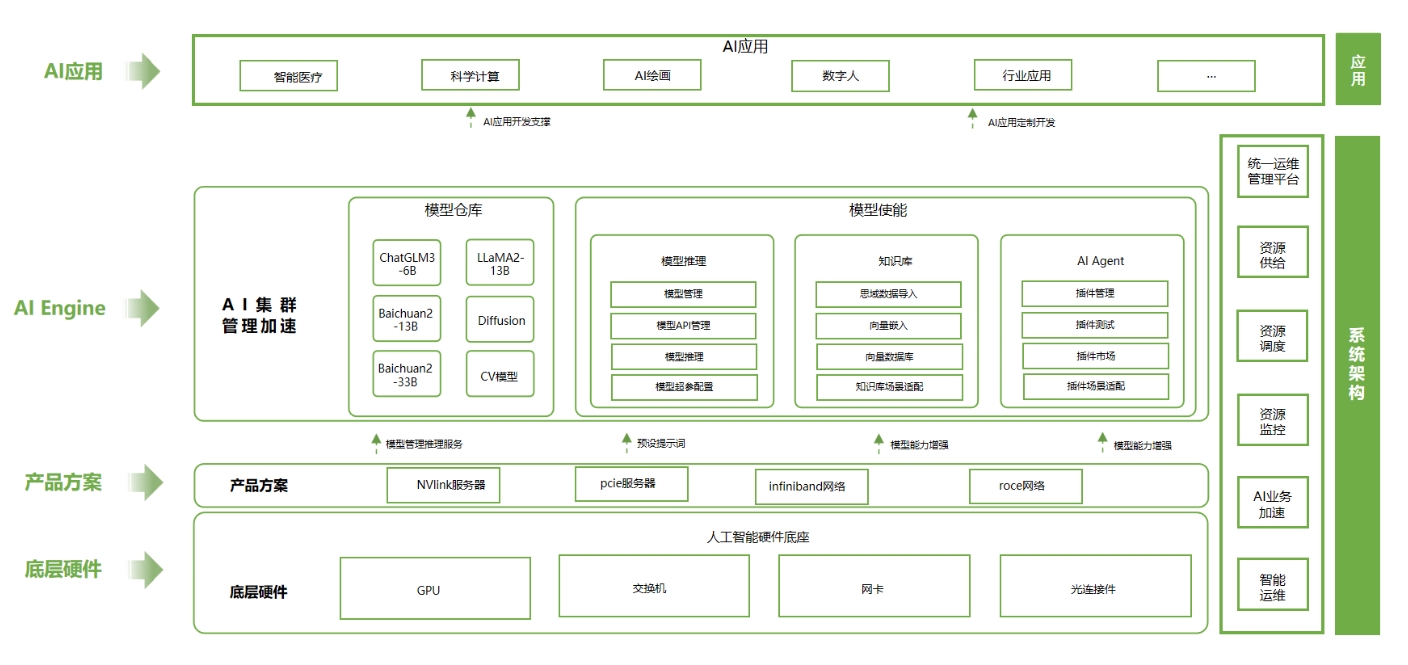
超擎AI Engine人工智能开发平台是一个开放高效的 AI 开发与部署平台,提供从数据处理、模型开发、训练到部署的全流程支持。平台集成了多种深度学习框架和容器管理工具,通过智能资源调度和可视化界面,帮助用户高效利用计算资源,简化模型部署流程。借助对 NVAIE 的兼容性和灵活集成能力,超擎AI平台为企业提供了强大的 AI 开发和推理环境,助力各行业加速智能化转型。

实现计算、存储、网络统一调度和管理;内置容器集群,安全稳定可靠。
支持多模态大模型;支持模型推理、微调和多场景插件;支持GPU微调、推理的加速库、框架。
丰富的大模型应用开发组件,支持拖拉拽和简单配置即可完成应用开发;开发、测试、部署、运维一站式交付。
应用全链路监测,应用视角系统级调优;大模型应用、模型和算力资源分层解耦。
提供多种嵌入模型,增强私域数据检索准确率;优化数据质量,增强召回效果。
计算、网络、数据、AI应用全栈能力;建设部署、数据治理、大模型应用的定制开发服务。

公众号


电话

需求反馈
